Оптимизация производительности вставки и чтения в S3
Этот раздел сосредоточен на оптимизации производительности при чтении и вставке данных из S3 с использованием функций таблиц s3.
Урок, описанный в этом руководстве, может быть применен к другим реализациям объектного хранилища с их собственными специализированными функциями таблиц, таким как GCS и Azure Blob storage.
Перед настройкой потоков и блоков для улучшения производительности вставки мы рекомендуем пользователям понять механику вставок в S3. Если вы знакомы с механикой вставок или просто хотите краткие советы, пропустите к нашему примеру ниже.
Механика вставки (одиночный узел)
Два основных фактора, помимо размера оборудования, влияют на производительность и использование ресурсов механики вставки данных ClickHouse (для одиночного узла): размер блока вставки и параллелизм вставки.
Размер блока вставки
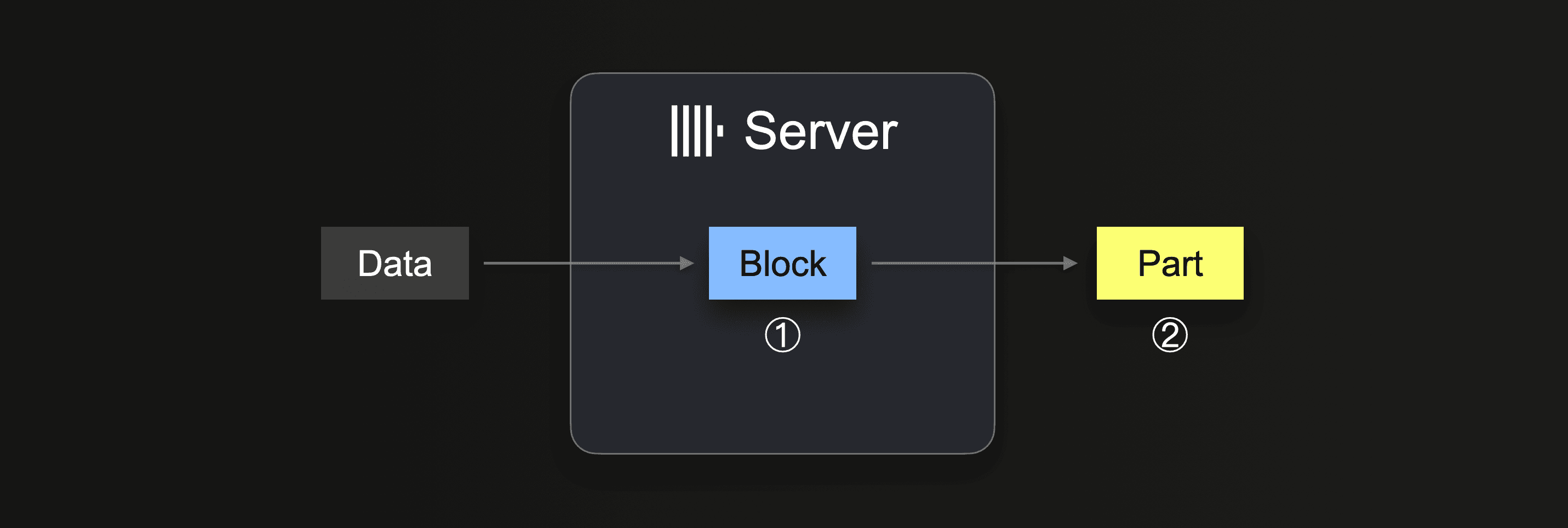
При выполнении INSERT INTO SELECT ClickHouse получает некоторую часть данных и ① формирует (по крайней мере) один блок вставки в памяти (на каждую ключ партиционирования) из полученных данных. Данные блока сортируются, и применяются оптимизации, специфические для движка таблицы. Затем данные сжимаются и ② записываются в хранилище базы данных в виде новой части данных.
Размер блока вставки влияет как на использование дискового ввода-вывода, так и на использование памяти сервера ClickHouse. Более крупные блоки вставки используют больше памяти, но создают более крупные и менее многочисленные исходные части. Чем меньше частей ClickHouse необходимо создать для загрузки большого объема данных, тем меньше требуются ввод-вывод диска и автоматические фоновая агрегация.
При использовании запроса INSERT INTO SELECT в сочетании с интеграционным движком таблицы или функцией таблицы данные забираются сервером ClickHouse:
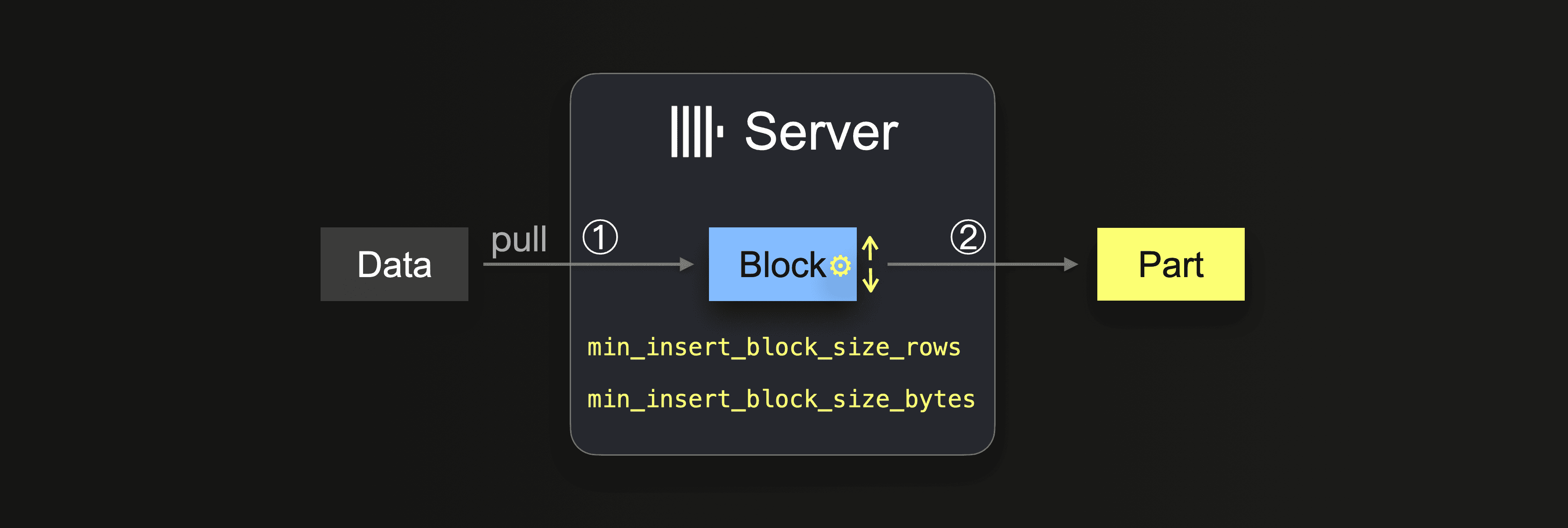
Пока данные полностью не загружены, сервер выполняет цикл:
В ① размер зависит от размера блока вставки, который можно контролировать с помощью двух настроек:
min_insert_block_size_rows(по умолчанию:1048545миллионов строк)min_insert_block_size_bytes(по умолчанию:256 MiB)
Когда либо указанное количество строк собрано в блоке вставки, либо достигнуто заданное количество данных (в зависимости от того, что произойдет первым), это приведет к записи блока в новую часть. Вставочный цикл продолжается с шага ①.
Обратите внимание, что значение min_insert_block_size_bytes обозначает не сжатый размер блока в памяти (а не размер сжатой части на диске). Также обратите внимание, что созданные блоки и части редко точно содержат указанное количество строк или байтов, потому что ClickHouse потоково и обрабатывает данные по-долговому-блочному. Поэтому эти настройки указывают минимальные пороговые значения.
Будьте осторожны с агрегацией
Чем меньше установленный размер блока вставки, тем больше исходных частей создается для большой загрузки данных, и тем больше фоновой агрегации выполняется одновременно со приемом данных. Это может вызвать конкуренцию за ресурсы (CPU и память) и потребовать дополнительного времени (для достижения здорового (3000) количества частей) после завершения загрузки.
Производительность запросов ClickHouse будет отрицательно затронута, если количество частей превысит рекомендуемые пределы.
ClickHouse будет непрерывно смешивать части в более крупные части, пока они не достигнут сжатого размера ~150 GiB. Эта схема показывает, как сервер ClickHouse объединяет части:
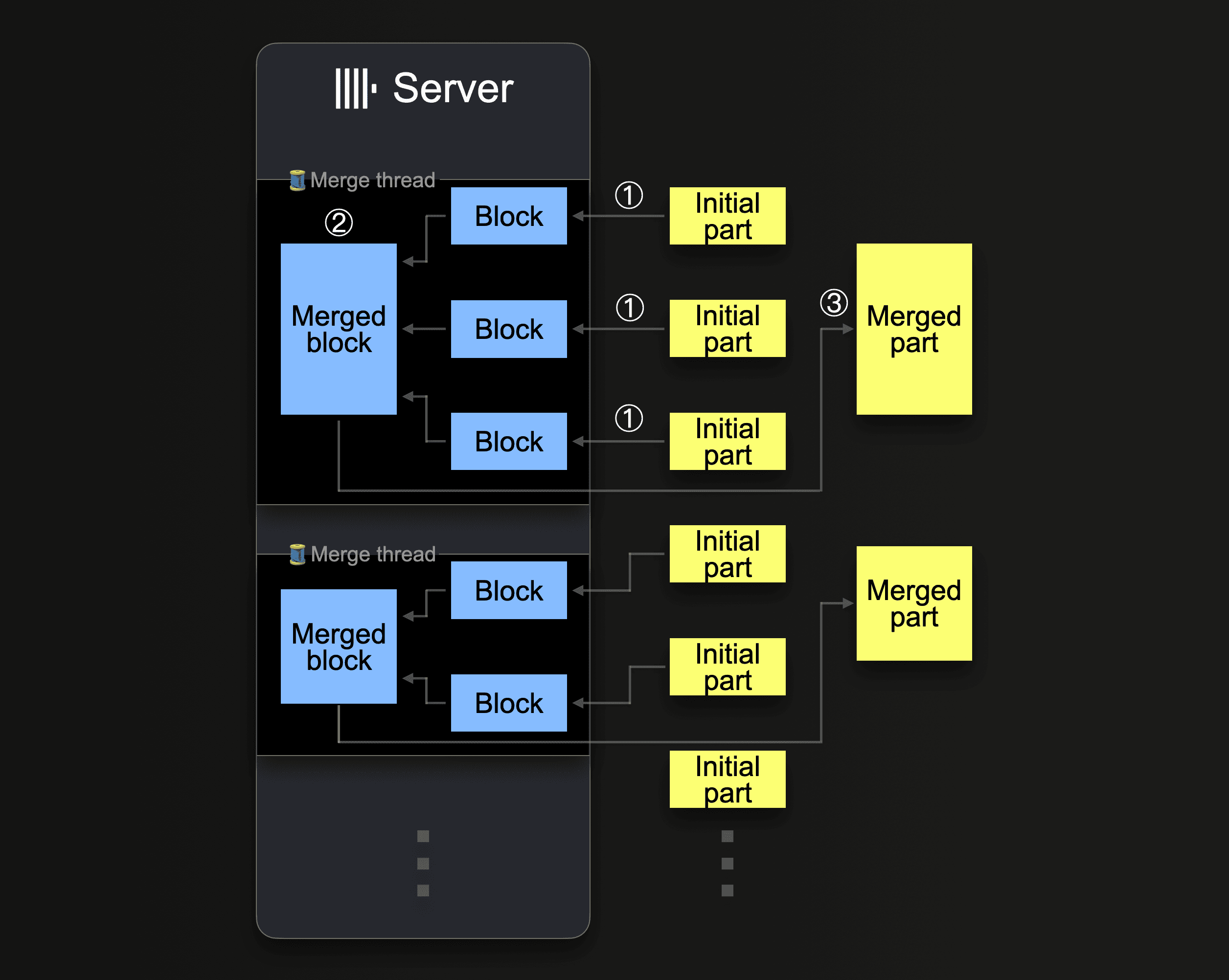
Один сервер ClickHouse использует несколько фонов пулов агрегации для выполнения параллельных агрегаций частей. Каждый поток выполняет цикл:
Обратите внимание, что увеличение числа ядер CPU и размера RAM увеличивает пропускную способность фоновой агрегации.
Части, которые были объединены в более крупные части, помечаются как неактивные и в конце концов удаляются после настраиваемого количества минут. Со временем это создает дерево объединенных частей (отсюда название MergeTree таблицы).
Параллелизм вставки
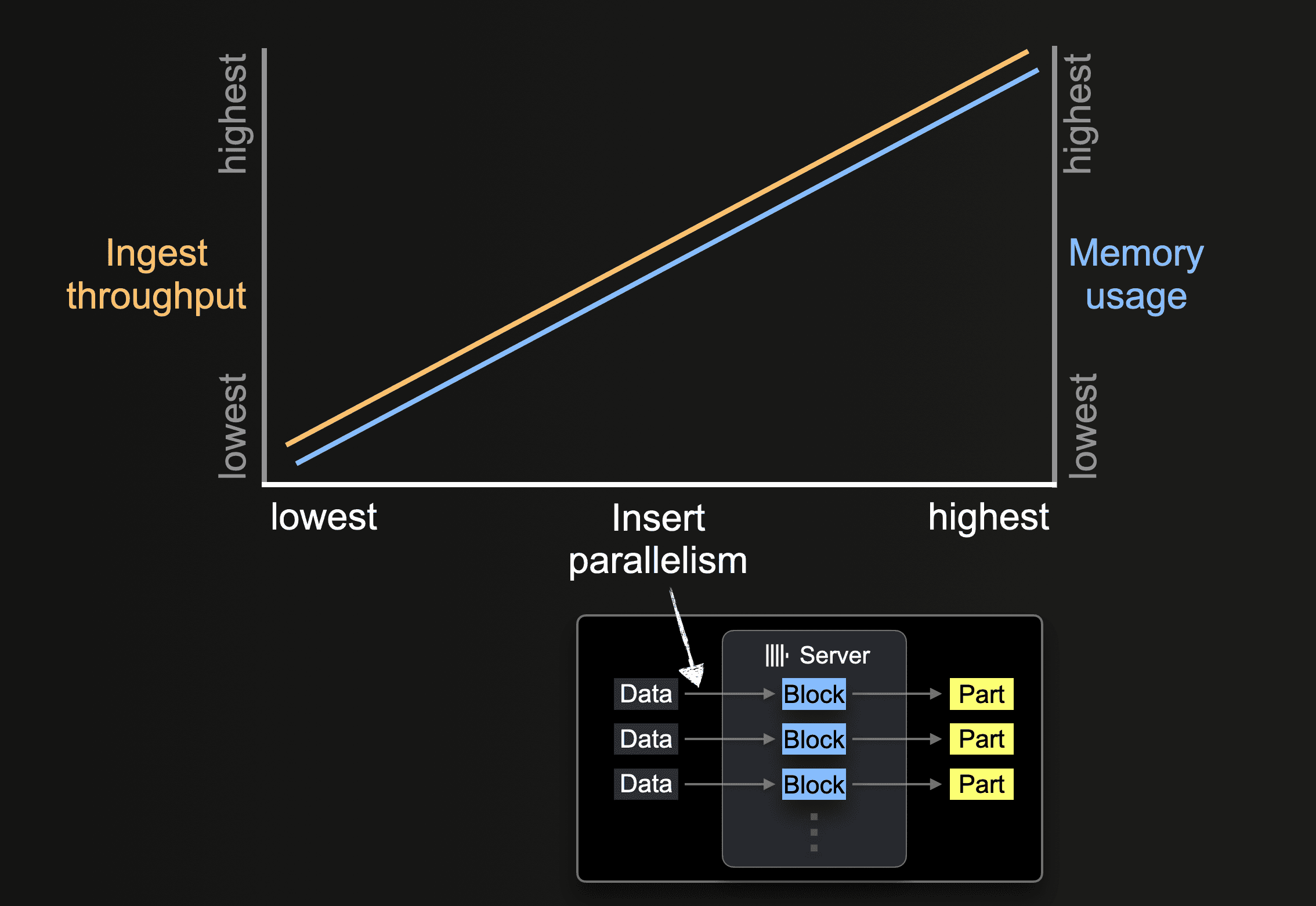
Сервер ClickHouse может обрабатывать и вставлять данные параллельно. Уровень параллелизма вставки влияет на пропускную способность и использование памяти сервера ClickHouse. Загрузка и обработка данных параллельно требует больше основной памяти, но увеличивает пропускную способность, так как данные обрабатываются быстрее.
Функции таблиц, такие как s3, позволяют указывать наборы имен файлов для загрузки с помощью шаблонов glob. Когда шаблон glob соответствует нескольким существующим файлам, ClickHouse может параллелизовать чтение этих файлов и вставлять данные параллельно в таблицу, используя параллельно выполняющиеся потоки вставки (на сервер):
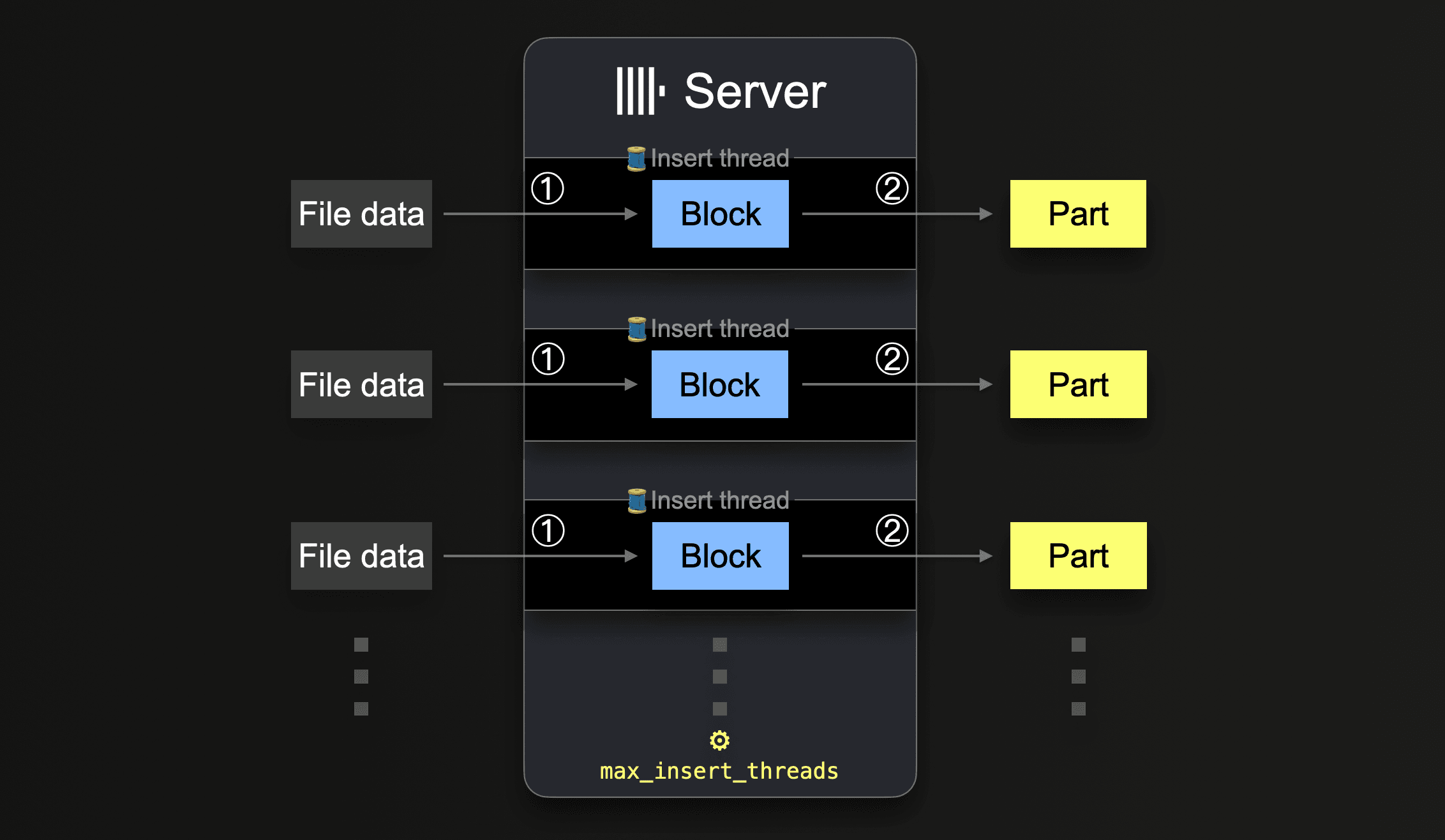
Пока все данные из всех файлов обрабатываются, каждый поток вставки выполняет цикл:
Количество таких параллельных потоков вставки можно настроить с помощью настройки max_insert_threads. Значение по умолчанию равно 1 для открытого исходного кода ClickHouse и 4 для ClickHouse Cloud.
С большим количеством файлов параллельная обработка несколькими потоками вставки работает хорошо. Она может полностью загрузить как доступные ядра CPU, так и пропускную способность сети (для параллельных загрузок файлов). В сценариях, когда будет загружено всего несколько крупных файлов, ClickHouse автоматически устанавливает высокий уровень параллелизма обработки данных и оптимизирует использование пропускной способности сети, создавая дополнительные потоки для чтения (загрузки) более различных диапазонов в крупных файлах параллельно.
Для функции и таблицы s3 параллельная загрузка отдельного файла определяется значениями max_download_threads и max_download_buffer_size. Файлы будут загружаться параллельно только в том случае, если их размер превышает 2 * max_download_buffer_size. По умолчанию значение max_download_buffer_size установлено на 10 MiB. В некоторых случаях вы можете без опасения увеличить этот размер буфера до 50 МБ (max_download_buffer_size=52428800), с целью гарантировать, что каждый файл будет загружен только одним потоком. Это может уменьшить время, которое каждый поток тратит на вызовы S3, и таким образом снизить время ожидания S3. Более того, для файлов, которые слишком малы для параллельного чтения, чтобы увеличить пропускную способность, ClickHouse автоматически загружает данные, заранее считывая такие файлы асинхронно.
Измерение производительности
Оптимизация производительности запросов с использованием функций таблиц S3 требуется как при выполнении запросов к данным на месте, т.е. при ад-хок запросах, когда используется только вычисление ClickHouse, и данные остаются в S3 в своем оригинальном формате, так и при вставке данных из S3 в движок таблиц ClickHouse MergeTree. Если не указано другое, следующие рекомендации применимы к обоим сценариям.
Влияние размера оборудования
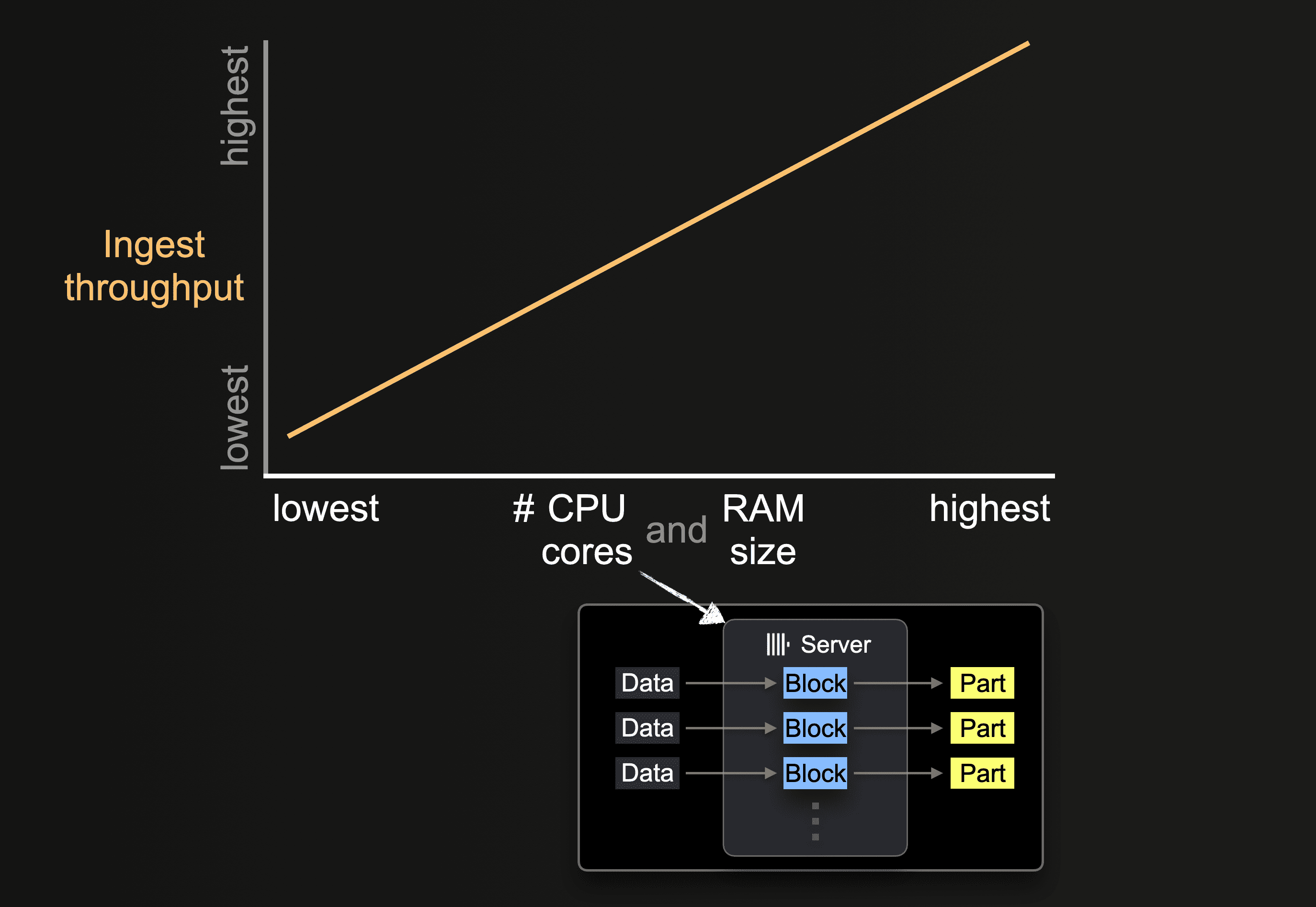
Количество доступных ядер CPU и размер RAM влияют на:
- поддерживаемый начальный размер частей
- возможный уровень параллелизма вставки
- пропускную способность фоновых агрегаций частей
и, следовательно, на общую пропускную способность загрузки.
Региональная локализация
Убедитесь, что ваши бакеты находятся в том же регионе, что и ваши экземпляры ClickHouse. Эта простая оптимизация может значительно улучшить производительность пропускной способности, особенно если вы разворачиваете свои экземпляры ClickHouse на инфраструктуре AWS.
Форматы
ClickHouse может читать файлы, хранящиеся в бакетах S3, в поддерживаемых форматах с использованием функции s3 и движка S3. Если читать «сырые» файлы, некоторые из этих форматов имеют явные преимущества:
- Форматы с закодированными именами колонок, такие как Native, Parquet, CSVWithNames и TabSeparatedWithNames, будут менее многословны для запроса, так как пользователю не потребуется указывать имя колонки в функции
s3. Имена колонок позволяют извлечь эту информацию. - Форматы будут различаться по производительности в отношении чтения и записи. Native и parquet представляют собой наиболее оптимальные форматы для производительности чтения, так как они уже ориентированы на столбцы и более компактны. Формат native также выигрывает от согласованности с тем, как ClickHouse хранит данные в памяти - тем самым уменьшая накладные расходы на обработку при потоковой передаче данных в ClickHouse.
- Размер блока часто влияет на задержку чтения больших файлов. Это очень заметно, если вы просто выбираете данные, например, возвращая первые N строк. В случае таких форматов, как CSV и TSV, файлы должны быть разобраны, чтобы вернуть набор строк. Форматы, такие как Native и Parquet, позволят быстрее выполнять выборку по этой причине.
- Каждый формат сжатия приносит свои плюсы и минусы, часто балансируя между уровнем сжатия для скорости и смещая производительность сжатия или распаковки. Если сжимать «сырые» файлы, такие как CSV или TSV, lz4 предлагает наиболее быструю производительность распаковки, жертвуя уровнем сжатия. Gzip, как правило, обеспечивает лучшее сжатие за счет немного медленных скоростей чтения. Xz идет дальше, обычно предлагая лучшее сжатие, но наиболее медленную производительность сжатия и распаковки. Если экспортируется, Gz и lz4 предлагают сопоставимые скорости сжатия. Учитывайте это в соотношении со скоростями подключения. Любые выгоды от более быстрого распаковки или сжатия будут легко нивелированы медленным подключением к вашим бакетам s3.
- Форматы, такие как native или parquet, обычно не оправдывают накладные расходы на сжатие. Любые экономии в размере данных, вероятно, будут минимальными, так как эти форматы изначально компактны. Время, затраченное на сжатие и распаковку, редко компенсирует время передачи по сети - особенно поскольку s3 глобально доступен с высокой пропускной способностью сети.
Пример набора данных
Чтобы проиллюстрировать дальнейшие потенциальные оптимизации, мы будем использовать посты из набора данных Stack Overflow - оптимизируя как производительность запроса, так и производительность вставки этих данных.
Этот набор данных состоит из 189 файлов Parquet, по одному на каждый месяц с июля 2008 года по март 2024 года.
Обратите внимание, что мы используем Parquet для производительности, следуя нашим вышеописанным рекомендациям, выполняя все запросы на кластере ClickHouse, расположенном в том же регионе, что и бакет. Этот кластер имеет 3 узла, каждый с 32 ГБ памяти и 8 vCPU.
Без настройки мы демонстрируем производительность вставки этого набора данных в движок таблиц MergeTree, а также выполнения запроса на подсчет пользователей, задающих наибольшее количество вопросов. Оба этих запроса намеренно требуют полного сканирования данных.
В нашем примере мы возвращаем только несколько строк. Если требуется измерить производительность запросов SELECT, при возвращении больших объемов данных клиенту, либо используйте null формат для запросов, либо направляйте результаты на Null engine. Это должно предотвратить перегрузку клиента данными и насыщение сети.
При чтении из запросов начальный запрос может показаться медленнее, чем если тот же запрос повторяется. Это может быть связано как с кешированием S3, так и с Кэшем вывода схемы ClickHouse. Это сохраняет выведенную схему файлов и означает, что шаг вывода можно пропустить при последующих обращениях, тем самым уменьшая время запроса.
Использование потоков для чтения
Производительность чтения из S3 будет линейно масштабироваться с количеством ядер, при условии, что вы не ограничены пропускной способностью сети или локальным ввода-вывода. Увеличение количества потоков также имеет комбинации накладных расходов на память, о которых пользователи должны знать. Следующие параметры можно изменить, чтобы потенциально улучшить производительность пропускной способности чтения:
- Обычно, значение по умолчанию для
max_threadsявляется достаточным, т.е. равное количеству ядер. Если количество памяти, используемой для запроса, велико, и это необходимо уменьшить, либо ограничение по результатам невелико, это значение можно установить ниже. Пользователи с достаточным количеством памяти могут попробовать увеличить это значение для возможного повышения пропускной способности чтения из S3. Обычно это полезно только на машинах с меньшим количеством ядер, т.е. < 10. Польза от дальнейшего параллелизма обычно уменьшается, поскольку другие ресурсы становятся узким местом, например, конкуренция между сетью и CPU. - Версии ClickHouse до 22.3.1 параллелизовали чтение только по нескольким файлам при использовании функции
s3или движкаS3. Это требовало от пользователя гарантировать, что файлы были разбиты на кусочки на S3 и читались с использованием шаблона glob для достижения оптимальной производительности чтения. Поздние версии теперь параллелизуют загрузки внутри файла. - В сценариях с низким количеством потоков пользователи могут извлечь выгоду, установив
remote_filesystem_read_methodв "read", чтобы инициировать синхронное чтение файлов из S3. - Для функции и таблицы s3 параллельная загрузка отдельного файла определяется значениями
max_download_threadsиmax_download_buffer_size. В то время какmax_download_threadsуправляет количеством используемых потоков, файлы будут загружаться параллельно только в том случае, если их размер превышает 2 *max_download_buffer_size. По умолчанию значениеmax_download_buffer_sizeустановлено на 10 MiB. В некоторых случаях вы можете безопасно увеличить этот размер буфера до 50 MB (max_download_buffer_size=52428800), с целью обеспечения того, чтобы большие файлы были загружены только одним потоком. Это может сократить время, которое каждый поток тратит на вызовы S3, и, таким образом, уменьшить время ожидания S3. См. этот блог для примера этого.
Перед внесением каких-либо изменений для улучшения производительности убедитесь, что вы корректно измеряете. Поскольку API вызовы S3 чувствительны к задержке и могут воздействовать на время клиента, используйте лог запросов для метрик производительности, т.е. system.query_log.
Рассмотрите наш предыдущий запрос, удвоение max_threads до 16 (по умолчанию max_thread равно количеству ядер на узле), улучшает производительность запроса чтения в 2 раза за счет большего использования памяти. Дальнейшее увеличение max_threads имеет уменьшенную отдачу, как показано.
Настройка потоков и размера блока для вставок
Чтобы достичь максимальной производительности инъекций, необходимо выбрать (1) размер блока вставки и (2) соответствующий уровень параллелизма вставки на основе (3) количества доступных ядер CPU и доступной памяти. В общем:
- Чем больше мы настраиваем размер блока вставки, тем меньше частей ClickHouse придется создать, и тем меньше дискового ввода-вывода и фоновая агрегация требуется.
- Чем выше мы настраиваем число параллельных потоков вставки, тем быстрее будут обрабатываться данные.
Существует противоречивый компромисс между этими двумя факторами производительности (плюс компромисс с фоновым слиянием частей). Количество доступной основной памяти серверов ClickHouse ограничено. Более крупные блоки используют больше основной памяти, что ограничивает количество параллельных потоков вставки, которые мы можем использовать. Напротив, большее количество параллельных потоков вставки требует больше основной памяти, так как количество потоков вставки определяет количество блоков вставки, созданных в памяти параллельно. Это ограничивает возможный размер блоков вставки. Кроме того, между потоками вставки и потоками фонового слияния может возникнуть конкуренция за ресурсы. Высокое количество настроенных потоков вставки (1) создает больше частей, которые требуют слияния и (2) отвлекает ядра CPU и пространство памяти от потоков фонового слияния.
Для подробного описания того, как поведение этих параметров влияет на производительность и ресурсы, мы рекомендуем прочитать этот блог. Как описано в этом блоге, настройка может потребовать осторожного баланса двух параметров. Эта исчерпывающая проверка часто является непрактичной, поэтому в общем мы рекомендуем:
С помощью этой формулы вы можете установить min_insert_block_size_rows в 0 (чтобы отключить порог на основе строк), в то время как max_insert_threads устанавливается на выбранное значение, а min_insert_block_size_bytes устанавливается на рассчитанный результат из приведенной выше формулы.
Используя эту формулу с нашим предыдущим примером Stack Overflow.
max_insert_threads=4(8 ядер на узел)peak_memory_usage_in_bytes- 32 ГБ (100% ресурсов узла) или34359738368байт.min_insert_block_size_bytes=34359738368/(3*4) = 2863311530
Как показано, настройка этих параметров улучшила производительность вставки более чем на 33%. Мы оставляем это читателю, чтобы посмотреть, сможет ли он дальше улучшить производительность одиночного узла.
Масштабирование с ресурсами и узлами
Масштабирование с ресурсами и узлами применяется как к чтению, так и к запросам вставки.
Вертикальное масштабирование
Все предыдущие настройки и запросы использовали только один узел в нашем кластере ClickHouse Cloud. Пользователи также часто имеют более одного доступного узла ClickHouse. Мы рекомендуем пользователям изначально масштабировать вертикально, улучшая пропускную способность S3 линейно с количеством ядер. Если мы повторим наши предыдущие вставочные и читательские запросы на большем узле ClickHouse Cloud с удвоенными ресурсами (64 ГБ, 16 vCPU) с соответствующими настройками, оба будут выполняться примерно в два раза быстрее.
Отдельные узлы также могут быть узким местом из-за сети и запросов S3 GET, что предотвращает линейное масштабирование производительности вверх.
Горизонтальное масштабирование
В конечном итоге, горизонтальное масштабирование часто необходимо из-за доступности оборудования и экономической эффективности. В ClickHouse Cloud производственные кластеры имеют как минимум 3 узла. Пользователи также могут захотеть использовать все узлы для вставки.
Использование кластера для чтения из S3 требует использования функции s3Cluster, как описано в Использование кластеров. Это позволяет распределить чтение между узлами.
Сервер, который изначально получает запрос на вставку, сначала разрешает шаблон glob, а затем динамически распределяет обработку каждого соответствующего файла между собой и другими серверами.
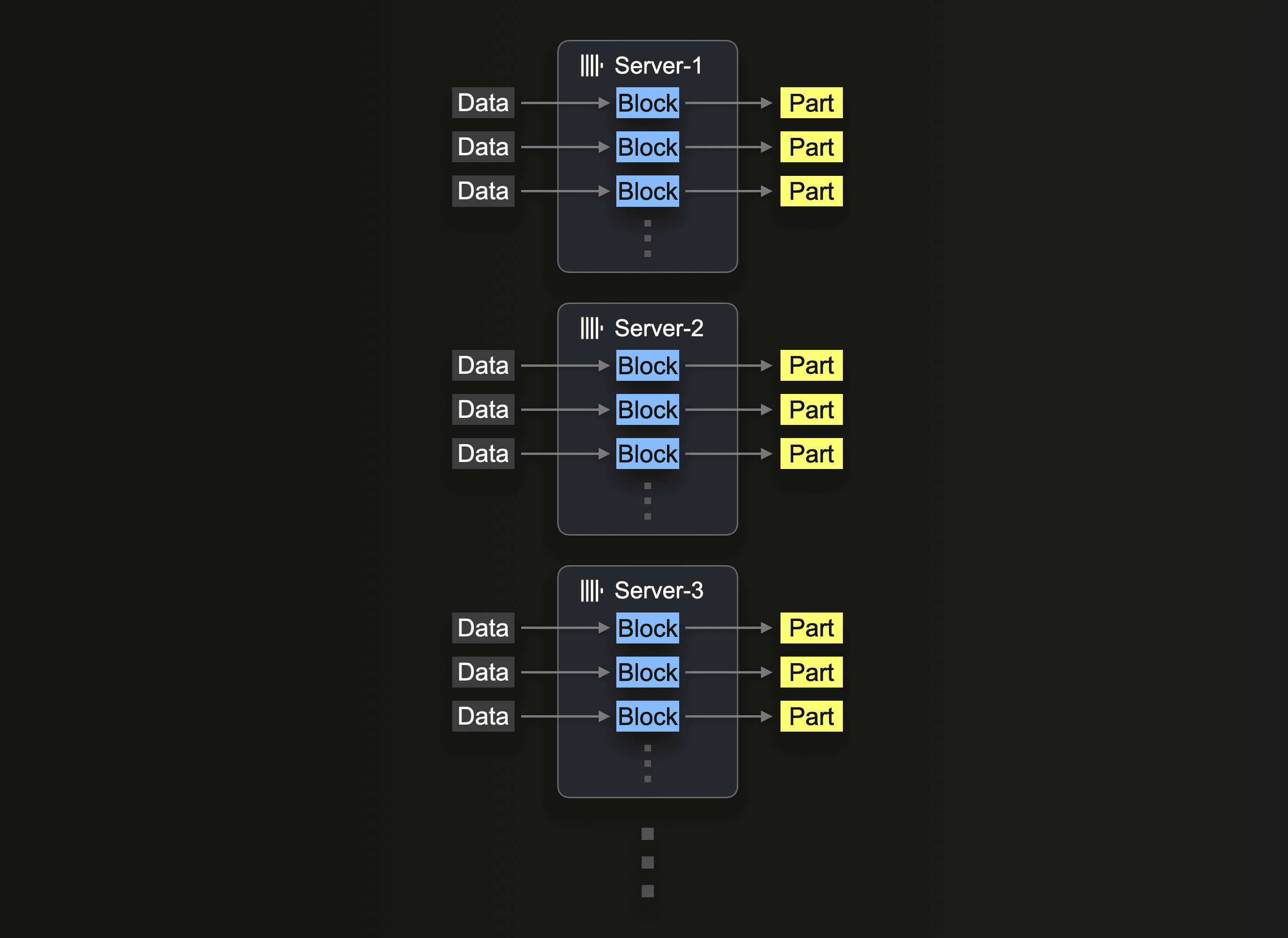
Мы повторяем наш предыдущий запрос, перераспределяя рабочую нагрузку между 3 узлами, изменяя запрос для использования s3Cluster. Это выполняется автоматически в ClickHouse Cloud, ссылаясь на кластер default.
Как отмечается в Использовании кластеров, эта работа распределяется на уровне файлов. Чтобы воспользоваться этой функцией пользователям потребуется достаточное количество файлов, т.е. более количества узлов.
Аналогичным образом, наш запрос на вставку может быть распределен, используя улучшенные настройки, идентифицированные ранее для одиночного узла:
Читатели заметят, что чтение файлов улучшило производительность запроса, но не вставки. По умолчанию, хотя чтения распределяются с использованием s3Cluster, вставки будут происходить против инициирующего узла. Это означает, что в то время как чтения происходят на каждом узле, итоговые строки будут направлены к инициатору для распределения. В сценариях с высоким пропуском это может оказаться узким местом. Чтобы это исправить, установите параметр parallel_distributed_insert_select для функции s3cluster.
Установка этого параметра в parallel_distributed_insert_select=2 гарантирует, что SELECT и INSERT будут выполняться на каждом шардированном узле, от/к базовой таблицы распределенного движка.
Как и ожидалось, это снижает производительность вставки в 3 раза.
Дальнейшая настройка
Отключение дедупликации
Операции вставки иногда могут завершаться неудачно из-за ошибок, таких как тайм-ауты. Когда вставки происходят неудачно, данные могли быть успешно вставлены или нет. Чтобы позволить клиенту безопасно повторить вставки, по умолчанию в распределенных развертываниях, таких как ClickHouse Cloud, ClickHouse пытается определить, были ли данные уже успешно вставлены. Если вставленные данные помечены как дубликаты, ClickHouse не вставляет их в целевую таблицу. Однако пользователь все равно получит статус успешной операции, как будто данные были вставлены нормально.
Хотя такое поведение, которое накладывает накладные расходы на вставку, имеет смысл при загрузке данных от клиента или пакетно, оно может быть ненужным при выполнении INSERT INTO SELECT из объектного хранилища. Отключив эту функциональность во время вставки, мы можем улучшить производительность, как показано ниже:
Оптимизация при вставке
В ClickHouse настройка optimize_on_insert управляет тем, будет ли происходить слияние частей данных в процессе вставки. Когда эта функция включена (optimize_on_insert = 1 по умолчанию), маленькие части сливаются в более крупные по мере их вставки, что улучшает производительность запросов за счет уменьшения числа частей, которые необходимо считать. Однако это слияние добавляет накладные расходы к процессу вставки, что может замедлить вставки с высокой пропускной способностью.
Отключение этой настройки (optimize_on_insert = 0) пропускает слияние во время вставок, позволяя данным записываться быстрее, особенно при частых маленьких вставках. Процесс слияния откладывается на фон, что позволяет улучшить производительность вставки, но временно увеличивает количество маленьких частей, что может замедлить запросы до завершения фонового слияния. Эта настройка идеальна, когда производительность вставки является приоритетом, и фоновый процесс слияния может эффективно обработать оптимизацию позже. Как показано ниже, отключение настройки может улучшить пропускную способность вставки:
Разные заметки
- Для сценариев с низким объемом памяти рассмотрите возможность снижения
max_insert_delayed_streams_for_parallel_write, если вставляете в S3.