Интеграция dbt и ClickHouse
dbt (инструмент построения данных) позволяет инженерам аналитики преобразовывать данные в своих хранилищах, просто написав операторы select. dbt обрабатывает материализацию этих операторов select в объекты в базе данных в форме таблиц и представлений, выполняя T из Extract Load and Transform (ELT). Пользователи могут создавать модели, определяемые оператором SELECT.
Внутри dbt эти модели могут ссылаться друг на друга и быть структурированы так, чтобы позволить создание концепций более высокого уровня. Шаблонный SQL, необходимый для соединения моделей, автоматически генерируется. Более того, dbt определяет зависимости между моделями и обеспечивает их создание в соответствующем порядке с использованием ориентированного ациклического графа (DAG).
Dbt совместим с ClickHouse через плагин, поддерживаемый ClickHouse. Мы описываем процесс подключения ClickHouse с простым примером на основе общедоступного набора данных IMDB. Мы также подчеркиваем некоторые из ограничений текущего соединителя.
Концепции
dbt вводит концепцию модели. Это определяется как SQL-оператор, потенциально объединяющий множество таблиц. Модель может быть "материализована" несколькими способами. Материализация представляет стратегию построения для select-запроса модели. Код, связанный с материализацией, — это шаблонный SQL, который оборачивает ваш SELECT-запрос в оператор для создания нового или обновления уже существующего отношения.
dbt предоставляет 4 типа материализации:
- представление (по умолчанию): Модель создается как представление в базе данных.
- таблица: Модель создается как таблица в базе данных.
- временная: Модель непосредственно не создается в базе данных, а вместо этого включается в зависимые модели в качестве общих табличных выражений.
- инкрементальная: Модель изначально материализуется как таблица, а в последующих запусках dbt вставляет новые строки и обновляет измененные строки в таблице.
Дополнительный синтаксис и предложения определяют, как эти модели должны обновляться, если их исходные данные изменяются. dbt обычно рекомендует начинать с материализации представления, пока производительность не станет проблемой. Материализация таблицы обеспечивает улучшение производительности времени запроса за счет захвата результатов запроса модели как таблицы, что приводит к увеличению объема хранимых данных. Инкрементальный подход строится на этом дальше, чтобы позволить захватывать последующие обновления исходных данных в целевой таблице.
Текущий плагин для ClickHouse поддерживает представление, таблицу, временную и инкрементальную материализации. Плагин также поддерживает снимки и сиды, которые мы исследуем в этом руководстве.
Для следующих руководств мы предполагаем, что у вас есть доступ к экземпляру ClickHouse.
Настройка dbt и плагина ClickHouse
dbt
Мы предполагаем использование dbt CLI для следующих примеров. Пользователи также могут рассмотреть dbt Cloud, который предлагает веб-основу, позволяющую пользователям редактировать и запускать проекты.
dbt предлагает несколько вариантов установки CLI. Следуйте инструкциям, описанным здесь. На этом этапе установите только dbt-core. Мы рекомендуем использовать pip.
Важно: Следующее проверено на python 3.9.
Плагин ClickHouse
Установите плагин dbt ClickHouse:
Подготовка ClickHouse
dbt отлично справляется с моделированием высоко реляционных данных. В целях примера мы предоставляем небольшую выборку данных IMDB с следующей реляционной схемой. Этот набор данных взят из репозитория реляционных наборов данных. Это тривиально по сравнению с общими схемами, используемыми с dbt, но представляет собой управляемую выборку:
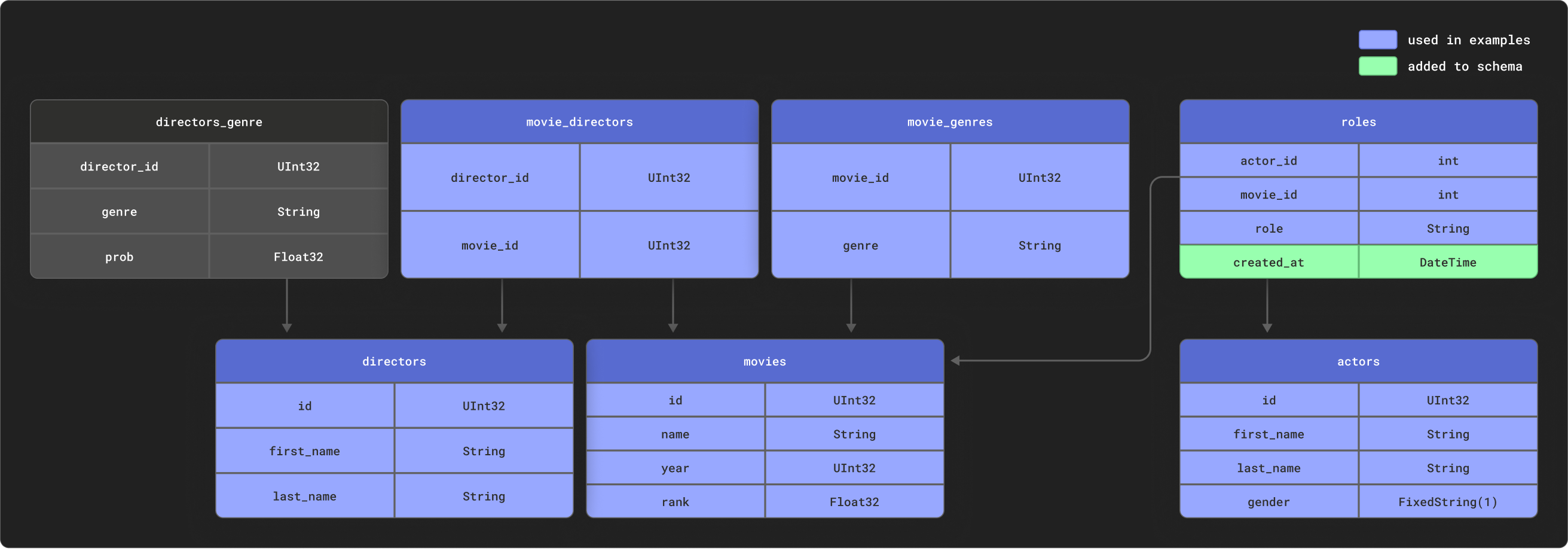
Мы используем подмножество этих таблиц, как показано.
Создайте следующие таблицы:
Столбец created_at для таблицы roles по умолчанию принимает значение now(). Мы используем это позже, чтобы определить инкрементальные обновления наших моделей - см. Инкрементальные модели.
Мы используем функцию s3, чтобы прочитать исходные данные из общедоступных конечных точек для вставки данных. Выполните следующие команды, чтобы заполнить таблицы:
Время выполнения этих команд может варьироваться в зависимости от вашей пропускной способности, но каждая должна занять всего несколько секунд для завершения. Выполните следующий запрос, чтобы вычислить сводку по каждому актеру, упорядочивая по количеству появлений в фильмах, и подтвердить, что данные загружены успешно:
Ответ должен выглядеть так:
В следующих руководствах мы преобразуем этот запрос в модель - материализуем его в ClickHouse как представление и таблицу dbt.
Подключение к ClickHouse
-
Создайте проект dbt. В данном случае мы назовем его в честь нашего источника
imdb. Когда вам будет предложено, выберитеclickhouseв качестве источника базы данных. -
Перейдите в папку вашего проекта:
-
На этом этапе вам потребуется текстовый редактор на ваш выбор. В следующих примерах мы используем популярный VS Code. Открыв каталог IMDB, вы должны увидеть коллекцию файлов yml и sql:
-
Обновите файл
dbt_project.yml, чтобы указать нашу первую модель -actor_summaryи установить профиль наclickhouse_imdb.

-
Далее нам необходимо предоставить dbt данные для подключения к нашему экземпляру ClickHouse. Добавьте следующее в файл
~/.dbt/profiles.yml.Обратите внимание на необходимость изменения пользователя и пароля. Есть дополнительные доступные настройки, документированные здесь.
-
Из каталога IMDB выполните команду
dbt debug, чтобы подтвердить, может ли dbt подключаться к ClickHouse.Подтвердите, что ответ включает
Тест подключения: [OK подключение успешно], указывающее на успешное подключение.
Создание простой материализации представления
При использовании материализации представления модель восстанавливается как представление при каждом запуске с помощью оператора CREATE VIEW AS в ClickHouse. Это не требует дополнительных затрат на хранение данных, но будет медленнее для выполнения запросов, чем материализации таблиц.
-
Из папки
imdbудалите каталогmodels/example: -
Создайте новый файл в каталоге
actorsвнутри папкиmodels. Здесь мы создаем файлы, каждый из которых представляет модель актера: -
Создайте файлы
schema.ymlиactor_summary.sqlв папкеmodels/actors.Файл
schema.ymlопределяет наши таблицы. Эти таблицы впоследствии будут доступны для использования в макросах. Отредактируйте файлmodels/actors/schema.yml, чтобы он содержал следующий контент:Файл
actors_summary.sqlопределяет нашу фактическую модель. Обратите внимание, что в функции конфигурации мы также запрашиваем, чтобы модель была материализирована как представление в ClickHouse. Наши таблицы ссылаются на файлschema.ymlчерез функциюsource, например,source('imdb', 'movies')относится к таблицеmoviesв базе данныхimdb. Отредактируйте файлmodels/actors/actors_summary.sql, чтобы он содержал следующий контент:Обратите внимание, как мы включаем столбец
updated_atв нашу финальную actor_summary. Мы используем это позже для инкрементальных материализаций. -
Из каталога
imdbвыполните командуdbt run. -
dbt представит модель как представление в ClickHouse, как и запрашивалось. Теперь мы можем запросить это представление напрямую. Это представление будет создано в базе данных
imdb_dbt- это определяется параметром схемы в файле~/.dbt/profiles.ymlпод профилемclickhouse_imdb.Запрашивая это представление, мы можем воспроизвести результаты нашего предыдущего запроса с более простой синтаксисом:
Создание материализации таблицы
В предыдущем примере наша модель была материализирована как представление. Хотя это может быть достаточно для некоторых запросов, более сложные SELECT или часто выполняемые запросы могут быть лучше материализированы как таблица. Эта материализация полезна для моделей, которые будут запрашиваться BI-инструментами, чтобы обеспечить более быстрое взаимодействие пользователей. Это фактически вызывает хранение результатов запроса как новой таблицы с соответствующими затратами на хранение - фактически выполняется INSERT TO SELECT. Обратите внимание, что эта таблица будет воссоздаваться каждый раз, то есть она не инкрементальная. Большие наборы данных могут, следовательно, привести к длительным временам выполнения - см. Ограничения dbt.
-
Измените файл
actors_summary.sqlтак, чтобы параметрmaterializedбыл установлен наtable. Обратите внимание, как определяетсяORDER BY, и обратите внимание, что мы используем движок таблицMergeTree: -
Из каталога
imdbвыполните командуdbt run. Это выполнение может занять немного больше времени - около 10с на большинстве машин. -
Подтвердите создание таблицы
imdb_dbt.actor_summary:Вы должны увидеть таблицу с соответствующими типами данных:
-
Подтвердите, что результаты из этой таблицы согласуются с предыдущими ответами. Обратите внимание на заметное улучшение времени ответа теперь, когда модель является таблицей:
Не стесняйтесь выполнять другие запросы к этой модели. Например, какие актеры имеют фильмы с наивысшим рейтингом и более чем 5 появлений?
Создание инкрементного материализованного представления
В предыдущем примере была создана таблица для материализации модели. Эта таблица будет перестраиваться при каждом выполнении dbt. Это может быть непрактично и крайне затратно для больших наборов результатов или сложных преобразований. Чтобы решить эту проблему и уменьшить время сборки, dbt предлагает инкрементные материализации. Это позволяет dbt вставлять или обновлять записи в таблице с момента последнего выполнения, что делает это подходящим для данных в формате событий. За кулисами создается временная таблица со всеми обновленными записями, а затем все неизмененные записи, а также обновленные записи вставляются в новую целевую таблицу. Это приводит к аналогичным ограничениям для больших наборов результатов, как и для модели таблицы.
Чтобы преодолеть эти ограничения для больших наборов, плагин поддерживает режим «inserts_only», в котором все обновления вставляются в целевую таблицу без создания временной таблицы (подробнее об этом ниже).
Чтобы проиллюстрировать этот пример, мы добавим актера "Clicky McClickHouse", который появится в потрясающих 910 фильмах - убедившись, что он появился в большем количестве фильмов, чем даже Mel Blanc.
-
Сначала мы изменяем нашу модель на инкрементную. Это добавление требует:
- unique_key - Для того чтобы плагин мог уникально идентифицировать строки, мы должны предоставить unique_key - в данном случае поле
idиз нашего запроса будет достаточно. Это гарантирует, что в нашей материализованной таблице не будет дубликатов строк. Для получения дополнительной информации об ограничениях уникальности, смотрите здесь. - Инкрементный фильтр - Мы также должны сказать dbt, как он должен определять, какие строки изменились в инкрементном запуске. Это достигается путем предоставления выражения дельты. Обычно это включает временную метку для событийных данных; следовательно, наше поле timestamp обновления. Этот столбец, который по умолчанию устанавливается в значение now() при вставке строк, позволяет идентифицировать новые роли. Кроме того, нам нужно определить альтернативный случай, когда добавляются новые актеры. Используя переменную
{{this}}, чтобы обозначить существующую материализованную таблицу, мы получаем выражениеwhere id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}}). Мы встраиваем это в условие{% if is_incremental() %}, чтобы убедиться, что оно используется только при инкрементных запусках, а не когда таблица впервые строится. Для получения дополнительной информации о фильтрации строк для инкрементальных моделей смотрите это обсуждение в документации dbt.
Обновите файл
actor_summary.sqlследующим образом:Обратите внимание, что наша модель будет реагировать только на обновления и добавления в таблицы
rolesиactors. Чтобы реагировать на все таблицы, пользователям рекомендуется разделять эту модель на несколько подмоделей - каждая со своим инкрементным критерием. Эти модели могут, в свою очередь, быть ссылаемы и соединены. Для получения дополнительной информации о перекрестных ссылках на модели смотрите здесь. - unique_key - Для того чтобы плагин мог уникально идентифицировать строки, мы должны предоставить unique_key - в данном случае поле
-
Выполните
dbt runи подтвердите результаты результирующей таблицы: -
Теперь мы добавим данные в нашу модель, чтобы проиллюстрировать инкрементное обновление. Добавим нашего актера "Clicky McClickHouse" в таблицу
actors: -
Пусть "Clicky" снимется в 910 случайных фильмах:
-
Подтвердите, что он на самом деле стал актером с наибольшим количеством появлений, запрашивая исходную таблицу и обходя любые модели dbt:
-
Выполните
dbt runи подтвердите, что наша модель была обновлена и совпадает с вышеуказанными результатами:
Внутренности
Мы можем идентифицировать выполненные операторы, чтобы достичь вышеуказанного инкрементного обновления, запросив журнал запросов ClickHouse.
Отрегулируйте вышеуказанный запрос по периоду выполнения. Мы оставим проверку результатов пользователю, но выделим общую стратегию, используемую плагином для выполнения инкрементных обновлений:
- Плагин создает временную таблицу
actor_sumary__dbt_tmp. Строки, которые изменились, передаются в эту таблицу. - Создается новая таблица
actor_summary_new. Строки из старой таблицы, в свою очередь, передаются из старой в новую, с проверкой, чтобы убедиться, что идентификаторы строк не существуют во временной таблице. Это эффективно обрабатывает обновления и дубликаты. - Результаты из временной таблицы передаются в новую таблицу
actor_summary: - Наконец, новая таблица атомарно заменяется старой версией с помощью оператора
EXCHANGE TABLES. Старая и временная таблицы в свою очередь удаляются.
Ниже это визуализируется:
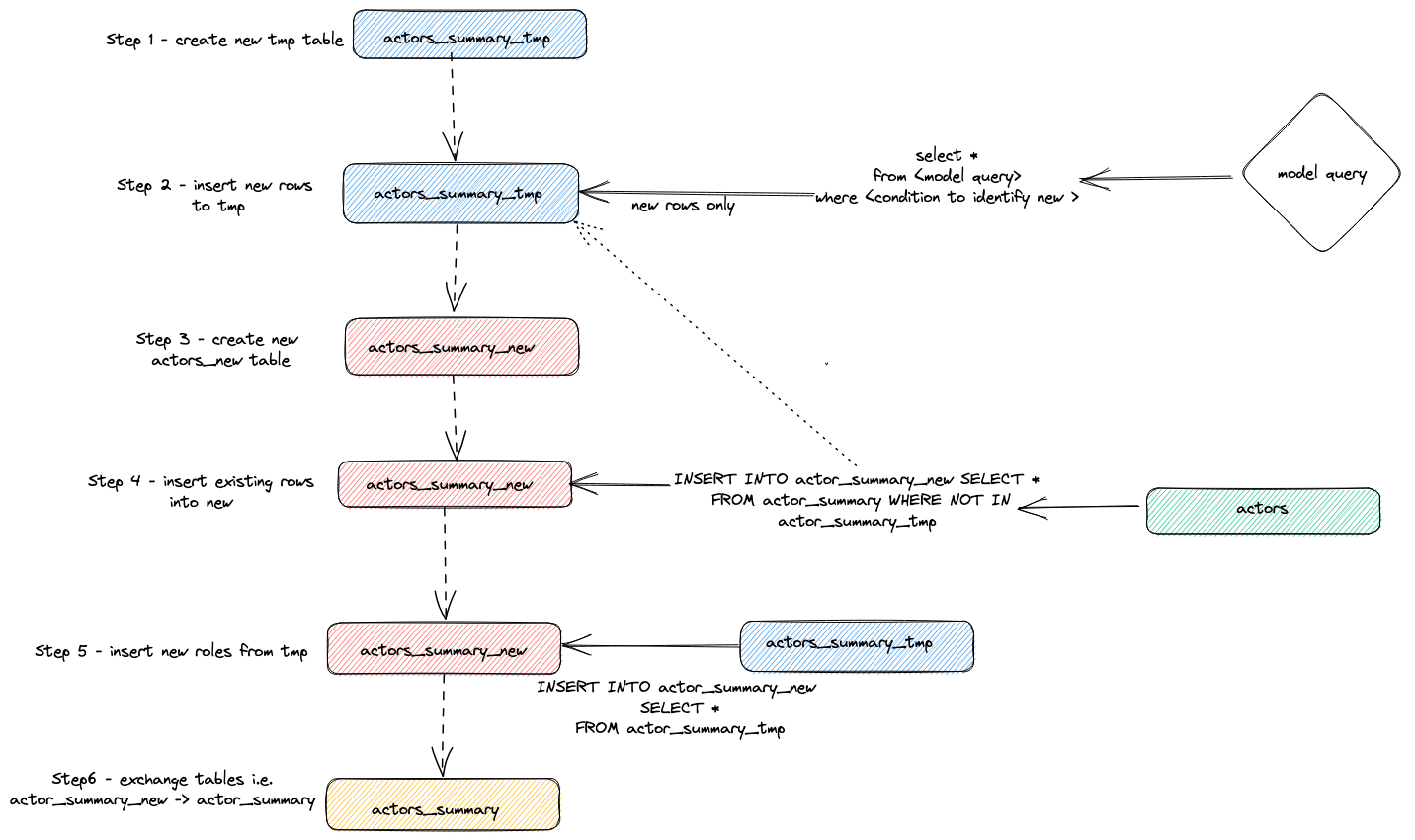
Эта стратегия может столкнуться с проблемами на очень больших моделях. Для получения дополнительной информации смотрите Ограничения.
Стратегия добавления (режим inserts-only)
Чтобы преодолеть ограничения больших наборов данных в инкрементальных моделях, плагин использует параметр конфигурации dbt incremental_strategy. Он может быть установлен в значение append. Когда он установлен, обновленные строки вставляются непосредственно в целевую таблицу (или imdb_dbt.actor_summary) и временная таблица не создается.
Примечание: Режим только добавления требует, чтобы ваши данные были неизменяемыми или чтобы дубликаты были приемлемы. Если вы хотите инкрементную модель таблицы, которая поддерживает измененные строки, не используйте этот режим!
Чтобы проиллюстрировать этот режим, мы добавим еще одного нового актера и повторно выполним dbt run с incremental_strategy='append'.
-
Настройте режим только добавления в actor_summary.sql:
-
Добавим другого известного актера - Дэнни ДеВито
-
Пусть Дэнни снимется в 920 случайных фильмах.
-
Выполните dbt run и подтвердите, что Дэнни был добавлен в таблицу actor-summary.
Обратите внимание, как это инкрементное обновление было гораздо быстрее по сравнению с вставкой "Clicky".
Проверка в таблице query_log показывает различия между двумя инкрементными запусками:
В этом запуске только новые строки добавляются напрямую в таблицу imdb_dbt.actor_summary, и создание таблицы не участвует.
Режим Delete+Insert (экспериментальный)
Исторически ClickHouse имел лишь ограниченную поддержку обновлений и удаления в форме асинхронных мутаций. Эти операции могут быть крайне ресурсоемкими и должны, как правило, избегаться.
ClickHouse 22.8 представил легковесные удаления. Эти операции в настоящее время экспериментальные, но предлагают более производительный способ удаления данных.
Этот режим может быть сконфигурирован для модели через параметр incremental_strategy, т.е.
Эта стратегия работает непосредственно с таблицей целевой модели, поэтому, если возникнет проблема во время выполнения операции, данные в инкрементной модели, вероятно, окажутся в недействительном состоянии - атомарного обновления нет.
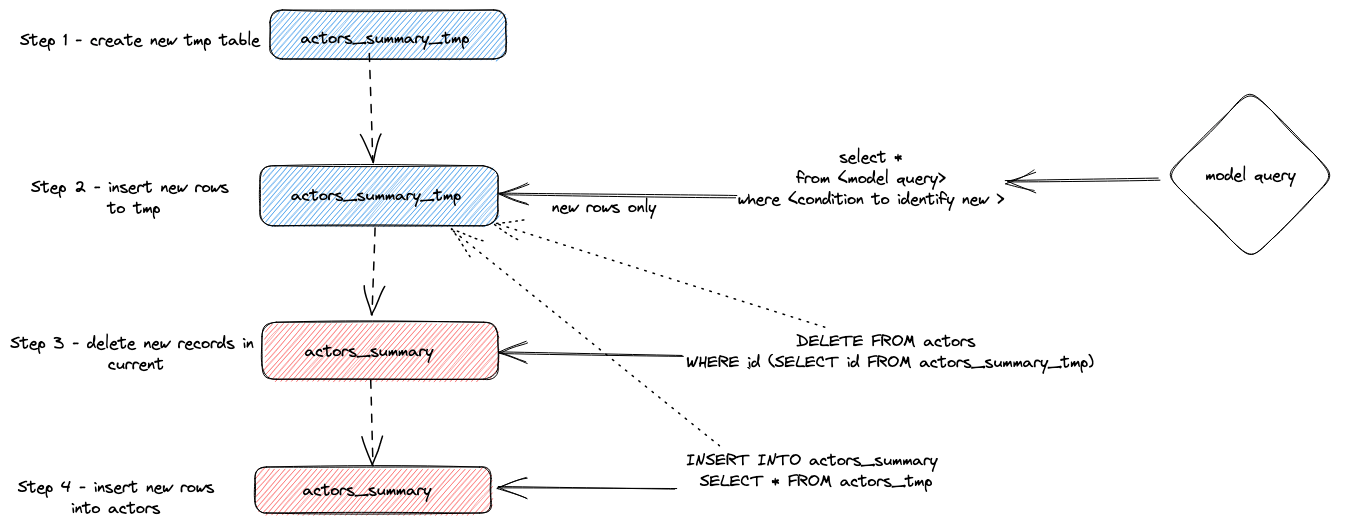
Вкратце, этот подход:
- Плагин создает временную таблицу
actor_sumary__dbt_tmp. Измененные строки передаются в эту таблицу. - Выполняется
DELETEдля текущей таблицыactor_summary. Строки удаляются по идентификатору изactor_sumary__dbt_tmp. - Строки из
actor_sumary__dbt_tmpвставляются вactor_summaryс помощьюINSERT INTO actor_summary SELECT * FROM actor_sumary__dbt_tmp.
Этот процесс показан ниже:
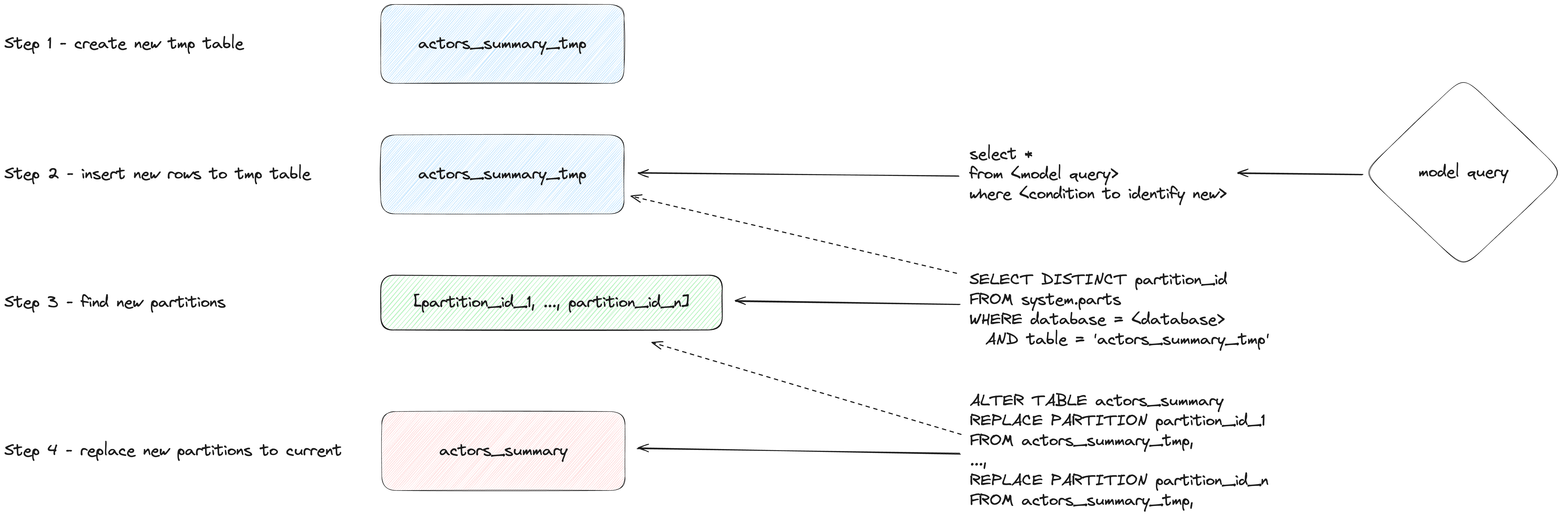
Режим insert_overwrite (экспериментальный)
Выполняет следующие действия:
- Создает промежуточную (временную) таблицу с такой же структурой, как у инкрементной модели:
CREATE TABLE {staging} AS {target}. - Вставляет только новые записи (созданные с помощью SELECT) в промежуточную таблицу.
- Заменяет только новые разделы (присутствующие в промежуточной таблице) в целевой таблице.
Этот подход имеет следующие преимущества:
- Он быстрее, чем стратегия по умолчанию, потому что не копирует всю таблицу.
- Он безопаснее, чем другие стратегии, потому что не изменяет оригинальную таблицу, пока операция INSERT не завершится успешно: в случае промежуточной ошибки оригинальная таблица не модифицируется.
- Он реализует "неизменяемость разделов" как лучшую практику в области инженерии данных. Что упрощает инкрементную и параллельную обработку данных, откаты и т.д.
Создание снимка
Снимки dbt позволяют зафиксировать изменения в изменяемой модели со временем. Это, в свою очередь, позволяет выполнять запросы по состоянию модели в определенный момент времени, когда аналитики могут "посмотреть назад во времени" на предыдущее состояние модели. Это достигается с помощью типов 2 медленно изменяющихся измерений, где столбцы from и to записывают, когда строка была действительной. Эта функциональность поддерживается плагином ClickHouse и показана ниже.
Этот пример предполагает, что вы завершили Создание инкрементной модели таблицы. Убедитесь, что ваш actor_summary.sql не устанавливает inserts_only=True. Ваши models/actor_summary.sql должны выглядеть следующим образом:
-
Создайте файл
actor_summaryв директории snapshots. -
Обновите содержимое файла actor_summary.sql следующими данными:
Несколько замечаний относительно этого содержимого:
- Запрос select определяет результаты, которые вы хотите зафиксировать с течением времени. Функция ref используется для ссылки на созданную ранее модель actor_summary.
- Нам требуется столбец временной метки, чтобы обозначить изменения записей. Наш столбец updated_at (смотрите Создание инкрементной модели таблицы) может быть использован здесь. Параметр strategy указывает на использование временной метки для обозначения обновлений, а параметр updated_at указывает на столбец, который использовать. Если этого нет в вашей модели, вы можете использовать стратегию проверки. Это значительно менее эффективно и требует от пользователя указания списка столбцов для сравнения. dbt сравнивает текущие и исторические значения этих столбцов, фиксируя любые изменения (или ничего не делает, если они идентичны).
-
Выполните команду
dbt snapshot.
Обратите внимание, что была создана таблица actor_summary_snapshot в базе данных snapshots (определяемой параметром target_schema).
-
При выборке этих данных вы увидите, что dbt добавил столбцы dbt_valid_from и dbt_valid_to. Последний имеет значения, установленные в null. Последующие запуски обновят это.
-
Пусть наш любимый актер Clicky McClickHouse появится еще в 10 фильмах.
-
Повторите команду dbt run из директории
imdb. Это обновит инкрементную модель. После завершения запустите dbt snapshot, чтобы зафиксировать изменения. -
Если теперь мы выполним запрос к нашему снимку, мы увидим, что у Clicky McClickHouse теперь 2 строки. Наша предыдущая запись теперь имеет значение dbt_valid_to. Наше новое значение записано с тем же значением в столбце dbt_valid_from и значением dbt_valid_to, установленным в null. Если бы у нас были новые строки, они также были бы добавлены в снимок.
Для получения дополнительной информации о снимках dbt смотрите здесь.
-
Выполните команду
dbt seed. Это создаст новую таблицуgenre_codesв нашей базе данныхimdb_dbt(как определено в нашей конфигурации схемы) с записями из нашего CSV-файла. -
Подтвердите, что они были загружены:
Ограничения
Текущий плагин ClickHouse для dbt имеет несколько ограничений, о которых пользователи должны быть осведомлены:
- Плагин в настоящее время материализует модели как таблицы с использованием
INSERT TO SELECT. Это эффективно означает дублирование данных. Очень большие наборы данных (PB) могут приводить к чрезвычайно длительному времени выполнения, что делает некоторые модели неприемлемыми. Стремитесь минимизировать количество строк, возвращаемых любым запросом, используя GROUP BY, где это возможно. Предпочитайте модели, которые суммируют данные, вместо тех, которые просто выполняют преобразование, сохраняя количество строк исходных данных. - Чтобы использовать Распределенные таблицы для представления модели, пользователи должны вручную создать основную реплицируемую таблицу на каждом узле. Распределенная таблица, в свою очередь, может быть создана на основе этих таблиц. Плагин не управляет созданием кластера.
- Когда dbt создает отношение (таблицу/представление) в базе данных, он обычно создает его в виде:
{{ database }}.{{ schema }}.{{ table/view id }}. ClickHouse не имеет понятия о схемах. Поэтому плагин использует{{schema}}.{{ table/view id }}, гдеschema– это база данных ClickHouse.
Дополнительная информация
Предыдущие руководства лишь затрагивают основные функции dbt. Пользователям рекомендуется ознакомиться с отличной документацией dbt.
Дополнительная конфигурация для плагина описана здесь.
Fivetran
Коннектор dbt-clickhouse также доступен для использования в преобразованиях Fivetran, что позволяет бесшовную интеграцию и возможности трансформации непосредственно в платформе Fivetran с использованием dbt.
Связанный контент
- Блог и вебинар: ClickHouse и dbt - Подарок от сообщества