Обзор Архитектуры
Это веб-версия нашей научной статьи VLDB 2024. Мы также вели блог о ее предыстории и пути, и рекомендуем посмотреть презентацию VLDB 2024, которую представил CTO ClickHouse и создатель, Алексей Миловидов:
АННОТАЦИЯ
За последние несколько десятилетий объем данных, которые хранятся и анализируются, увеличился в несколько раз. Бизнесы разных отраслей начали полагаться на эти данные для улучшения продуктов, оценки производительности и принятия критически важных бизнес-решений. Однако по мере того как объемы данных стали анализироваться на уровне Интернета, бизнесы должны были управлять историческими и новыми данными экономически эффективно и масштабируемо, при этом ожидая высокой скорости выполнения многопоточных запросов и задержек в реальном времени (например, менее одной секунды, в зависимости от использования).
Данная статья представляет обзор ClickHouse, популярной открытой OLAP базы данных, разработанной для высокопроизводительной аналитики на масштабах пета-байтовых наборов данных с высокими темпами загрузки. Ее уровень хранения комбинирует формат данных на основе традиционных деревьев слияния (LSM) с новыми методами непрерывной трансформации (например, агрегация, архивирование) исторических данных в фоновом режиме. Запросы пишутся на удобном диалекте SQL и обрабатываются современным векторизованным движком выполнения запросов с опциональной компиляцией кода. ClickHouse активно использует техники сокращения для избежания оценки неактуальных данных в запросах. Другие системы управления данными могут быть интегрированы на уровне табличной функции, движка таблицы или движка базы данных. Реальные бенчмарки демонстрируют, что ClickHouse является одной из самых быстрых аналитических баз данных на рынке.
1 ВВЕДЕНИЕ
В этой статье описывается ClickHouse, столбцовая OLAP база данных, предназначенная для высокопроизводительных аналитических запросов к таблицам с триллионами строк и сотнями колонок. ClickHouse был запущен в 2009 году как оператор фильтрации и агрегации для веб-аналитики логов и был открыт в 2016 году. Рисунок 1 иллюстрирует, когда основные функции, описанные в этой статье, были внедрены в ClickHouse.
ClickHouse предназначен для решения пяти ключевых задач современного управления аналитическими данными:
-
Огромные наборы данных с высокими темпами загрузки. Многие прикладные решения в таких отраслях, как веб-аналитика, финансы и электронная коммерция, характеризуются огромными и постоянно растущими объемами данных. Чтобы справляться с огромными наборами данных, аналитические базы данных не только должны предоставлять эффективные стратегии индексации и сжатия, но и позволять распределять данные между несколькими узлами (масштабирование) из-за ограниченности единственных серверов в несколько десятков терабайт. Более того, последние данные обычно более актуальны для получения инсайтов в реальном времени, чем исторические данные. Таким образом, аналитические базы данных должны иметь возможность загружать новые данные с постоянно высокими темпами или всплесками, а также непрерывно "уменьшать приоритет" (например, агрегация, архивирование) исторических данных без замедления параллельных запросов отчетности.
-
Множество одновременных запросов с ожиданием низкой задержки. Запросы можно в общем классифицировать на ad-hoc (например, исследовательский анализ данных) или регулярные (например, периодические запросы на панели управления). Чем более интерактивен случай использования, тем ниже ожидаемая задержка запросов, что создает вызовы в оптимизации и выполнении запросов. Регулярные запросы дополнительно предоставляют возможность адаптировать физическое расположение базы данных к нагрузке. В результате базы данных должны предлагать техники сокращения, позволяющие оптимизировать частые запросы. В зависимости от приоритета запроса базы данных должны также обеспечивать равный или приоритизированный доступ к общим системным ресурсам, таким как CPU, память, диск и ввод-вывод сети, даже если одновременно выполняется большое количество запросов.
-
Разнообразные ландшафты хранилищ данных, мест хранения и форматов. Чтобы интегрироваться с существующими архитектурами данных, современные аналитические базы данных должны обладать высокой степенью открытости для чтения и записи внешних данных в любой системе, местоположении или формате.
-
Удобный язык запросов с поддержкой анализа производительности. Реальное использование OLAP баз данных накладывает дополнительные "мягкие" требования. Например, вместо узкоспециального языка программирования пользователи часто предпочитают взаимодействовать с базами данных на выразительном диалекте SQL с вложенными типами данных и широким спектром обычных, агрегатных и оконных функций. Аналитические базы данных также должны предоставлять сложные инструменты для анализа производительности системы или отдельных запросов.
-
Надежность промышленного уровня и универсальность развертывания. Поскольку оборудование общего назначения ненадежно, базы данных должны предоставлять репликацию данных для обеспечения надежности при сбоях узлов. Кроме того, базы данных должны работать на любом оборудовании, от старых ноутбуков до мощных серверов. Наконец, чтобы избежать накладных расходов на сбор мусора в программах на основе JVM и обеспечить производительность на уровне "bare-metal" (например, SIMD), базы данных лучше всего развертываются как нативные двоичные файлы для целевой платформы.

Рисунок 1: Хронология ClickHouse.
2 АРХИТЕКТУРА
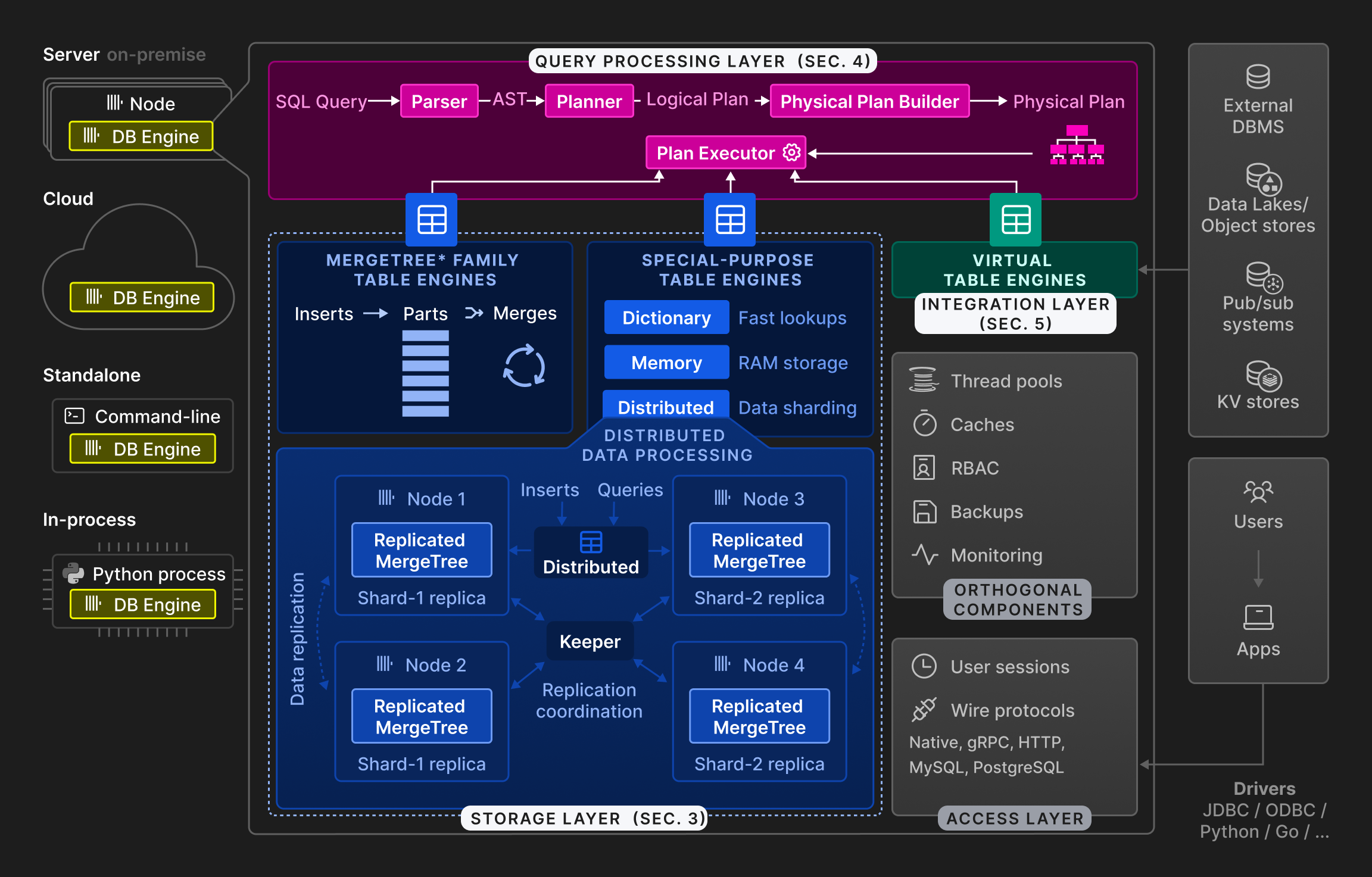
Рисунок 2: Высокоуровневая архитектура движка базы данных ClickHouse.
Как показано на Рисунке 2, движок ClickHouse разделен на три основных уровня: уровень обработки запросов (описан в разделе 4), уровень хранения (раздел 3) и уровень интеграции (раздел 5). Помимо этого, уровень доступа управляет пользовательскими сессиями и коммуникацией с приложениями через различные протоколы. Существуют ортогональные компоненты для многопоточности, кэширования, контроля доступа на основе ролей, резервного копирования и непрерывного мониторинга. ClickHouse написан на C++ как одно статически связанное бинарное приложение без зависимостей.
Обработка запросов следует традиционной парадигме разбора входящих запросов, построения и оптимизации логических и физических планов запросов, а также выполнения. ClickHouse использует векторизованную модель выполнения, схожую с MonetDB/X100 [11], в комбинации с оппортунистической компиляцией кода [53]. Запросы могут быть написаны на богатом функциональном диалекте SQL, PRQL [76], или KQL Кусто [50].
Уровень хранения состоит из различных движков таблицы, которые инкапсулируют формат и расположение данных таблицы. Движки таблицы делятся на три категории: первая категория - это семейство движков таблиц MergeTree*, которые представляют основной формат постоянного хранения в ClickHouse. Основываясь на идее деревьев слияния LSM [60], таблицы делятся на горизонтальные, отсортированные части, которые постоянно сливаются фоновым процессом. Индивидуальные движки таблиц MergeTree* отличаются тем, как слияние комбинирует строки из своих входных частей. Например, строки могут быть агрегированы или заменены, если устарели.
Вторая категория - это специализированные движки таблиц, которые используются для ускорения или распределения выполнения запросов. Эта категория включает в себя движки таблиц в памяти, называемые словарями. Словарь кэширует результат запроса, который периодически выполняется против внутреннего или внешнего источника данных. Это значительно снижает задержки доступа в сценариях, где допустим некоторый уровень устаревания данных. Другие примеры специализированных движков таблиц включают чистый в памяти движок, используемый для временных таблиц, и движок распределенных таблиц для прозрачного шардирования данных (см. ниже).
Третья категория движков таблиц - это виртуальные движки таблиц для двунаправленного обмена данными с внешними системами, такими как реляционные базы данных (например, PostgreSQL, MySQL), системы публикации/подписки (например, Kafka, RabbitMQ [24]) или key/value хранилища (например, Redis). Виртуальные движки также могут взаимодействовать с озерами данных (например, Iceberg, DeltaLake, Hudi [36]) или файлами в объектном хранилище (например, AWS S3, Google GCP).
ClickHouse поддерживает шардирование и репликацию таблиц по нескольким узлам кластера для масштабируемости и доступности. Шардирование делит таблицу на набор шардов таблицы в соответствии с выражением шардирования. Индивидуальные шардовые таблицы являются взаимозависимыми и обычно располагаются на разных узлах. Клиенты могут читать и записывать шардовые таблицы напрямую, т.е. относиться к ним как к отдельным таблицам, или использовать специальный движок распределенной таблицы, который предоставляет глобальный обзор всех шардов таблицы. Основная цель шардирования - обрабатывать наборы данных, превышающие ёмкость отдельных узлов (обычно несколько десятков терабайт данных). Другое использование шардирования заключается в распределении нагрузки на чтение-запись для таблицы между несколькими узлами, т.е. балансировке нагрузки. Ортогонально этому, шард может быть реплицирован по нескольким узлам для обеспечения отказоустойчивости от сбоев узлов. Для этой цели у каждого движка таблицы MergeTree* есть соответствующий движок ReplicatedMergeTree*, который использует многомастера координационную схему, основанную на консенсусе Raft [59] (реализованном Keeper, заменой Apache Zookeeper, написанной на C++), чтобы гарантировать, что каждый шард всегда имеет конфигурируемое количество реплик. Раздел 3.6 подробно обсуждает механизм репликации. В качестве примера Рисунок 2 показывает таблицу с двумя шардами, каждый из которых реплицирован на два узла.
Наконец, движок базы данных ClickHouse может работать в режимах on-premise, облачном, автономном или внутреннем. В режиме on-premise пользователи настраивают ClickHouse локально как единственный сервер или многузловой кластер с шардированием и/или репликацией. Клиенты взаимодействуют с базой данных через нативные, бинарные протоколы MySQL или PostgreSQL, или через HTTP REST API. Облачный режим представлен ClickHouse Cloud, полностью управляемым и автоматически масштабируемым предложением DBaaS. В то время как эта статья сосредоточена на режиме on-premise, мы планируем описать архитектуру ClickHouse Cloud в последующей публикации. Автономный режим превращает ClickHouse в утилиту командной строки для анализа и трансформации файлов, создавая его SQL-основанной альтернативой Unix инструментам, таким как cat и grep. Хотя это не требует предварительной настройки, автономный режим ограничен одним сервером. Недавно был разработан внутренний режим, называемый chDB [15], для интерактивного анализа данных, таких как Jupyter notebooks [37] с Pandas dataframes [61]. Вдохновленный DuckDB [67], chDB встраивает ClickHouse как высокопроизводительный OLAP движок в хост-программа. В сравнении с другими режимами, это позволяет передавать исходные и результирующие данные между движком базы данных и приложением эффективно без копирования, поскольку они работают в одном адресном пространстве.
3 УРОВЕНЬ ХРАНЕНИЯ
В этом разделе рассматриваются движки таблиц MergeTree* как нативный формат хранения ClickHouse. Мы описываем их представление на диске и обсуждаем три техники сокращения данных в ClickHouse. Затем мы представим стратегии слияния, которые непрерывно трансформируют данные, не влияя на одновременные вставки. Наконец, мы объясним, как реализуются обновления и удаления, а также дедупликация данных, репликация данных и соблюдение ACID.
3.1 Формат на диске
Каждая таблица в движке таблиц MergeTree* организована как коллекция неизменяемых частей таблицы. Часть создается всякий раз, когда набор строк вставляется в таблицу. Части существуют независимо, так как они включают все метаданные, необходимые для интерпретации их содержимого без дополнительных обращений к центральному каталогу. Чтобы сохранить число частей на таблицу низким, фоновая задача слияния периодически комбинирует несколько меньших частей в большую часть до тех пор, пока не достигнется настраиваемый размер части (по умолчанию 150 ГБ). Поскольку части отсортированы по колонкам первичного ключа таблицы (см. раздел 3.2), для слияния используется эффективная k-ходовая сортировка [40]. Исходные части помечаются как неактивные и в конечном итоге удаляются, как только их количество ссылок уменьшается до нуля, т.е. больше никаких запросов не считывают их.
Строки могут вставляться в двух режимах: В режиме синхронной вставки каждое предложение INSERT создает новую часть и добавляет её в таблицу. Чтобы минимизировать накладные расходы на слияния, клиентам базы данных рекомендуется вставлять кортежи партиями, например, 20,000 строк за раз. Однако задержки, вызванные пакетированием на стороне клиента, часто недопустимы, если данные должны анализироваться в реальном времени. Например, сценарии наблюдаемости часто включают в себя тысячи агентов мониторинга, которые постоянно отправляют небольшие объемы данных о событиях и метриках. Такие сценарии могут использовать режим асинхронной вставки, в котором ClickHouse буферизует строки из нескольких входящих INSERT в одну и ту же таблицу и создает новую часть только после превышения размера буфера настраиваемого порога или истечения времени ожидания.
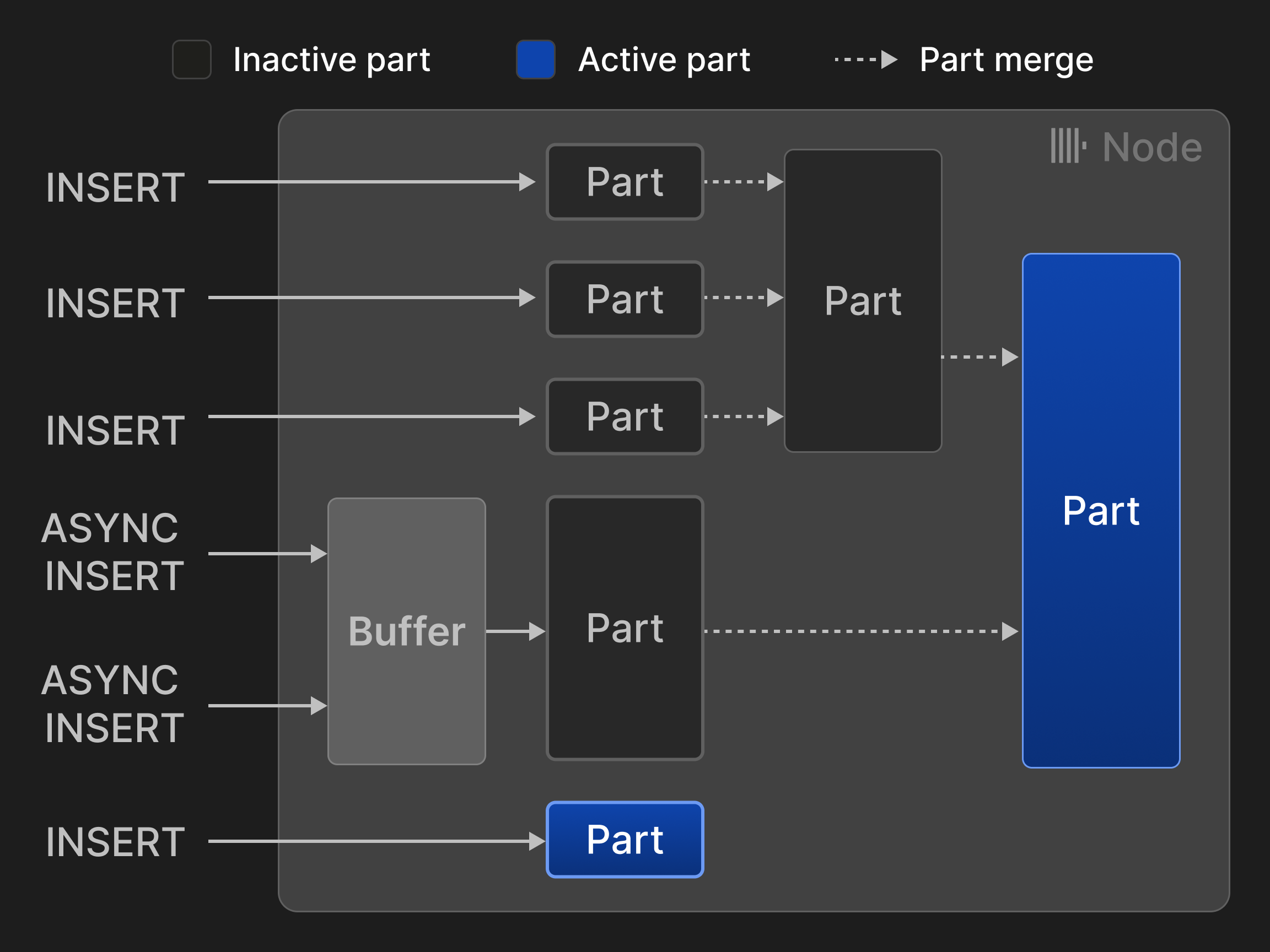
Рисунок 3: Вставки и слияния для таблиц в движке MergeTree*.
Рисунок 3 иллюстрирует четыре синхронные и две асинхронные вставки в таблицу движка MergeTree*. Два слияния сократили количество активных частей с первоначальных пяти до двух.
По сравнению с деревьями LSM [58] и их реализациями в различных базах данных [13, 26, 56], ClickHouse рассматривает все части как равные, вместо того чтобы организовывать их в иерархию. В результате слияния больше не ограничиваются частями на одном уровне. Поскольку это также отказывается от неявного хронологического порядка частей, требуются альтернативные механизмы для обновлений и удалений, не основанные на tombstones (см. раздел 3.4). ClickHouse записывает вставки непосредственно на диск, тогда как другие базы данных, основанные на LSM-деревьях, обычно используют ведущее журналирование (см. раздел 3.7).
Часть соответствует каталогу на диске, содержащему один файл для каждого столбца. В качестве оптимизации, столбцы маленькой части (меньше 10 МБ по умолчанию) хранятся последовательно в одном файле для повышения пространственной локальности для чтения и записи. Строки части дополнительно логически делятся на группы по 8192 записи, называемые гранулами. Гранула представляет собой наименьшую неделимую единицу данных, обрабатываемую операторами сканирования и индексного поиска в ClickHouse. Чтения и записи на диске, однако, не выполняются на уровне гранулы, а на уровне блоков, которые объединяют несколько соседних гранул в одном столбце. Новые блоки формируются на основе настройки размера в байтах на блок (по умолчанию 1 МБ), т.е. количество гранул в блоке переменное и зависит от типа и распределения данных в столбце. Блоки ещё сжимаются для уменьшения их размера и затрат ввода-вывода. По умолчанию ClickHouse использует LZ4 [75] как общий алгоритм сжатия, но пользователи также могут задавать специализированные кодеки, такие как Gorilla [63] или FPC [12] для данных с плавающей запятой. Алгоритмы сжатия могут также быть связаны в цепочку. Например, возможно сначала уменьшить логическую избыточность в числовых значениях с помощью дельта-кодирования [23], затем выполнить интенсивное сжатие и, наконец, зашифровать данные с использованием кодека AES. Блоки распаковываются "на лету", когда они загружаются с диска в память. Чтобы обеспечить быстрый случайный доступ к отдельным гранулам, несмотря на сжатие, ClickHouse дополнительно хранит для каждого столбца отображение, которое связывает каждый идентификатор гранулы с оффсетом его содержащего сжатого блока в файле столбца и оффсетом гранулы в несжатом блоке.
Столбцы также могут быть закодированы в словарях [2, 77, 81] или сделаны допускающими нулевые значения, используя два специальных оборачивающих типа данных: LowCardinality(T) заменяет оригинальные значения столбца на целочисленные идентификаторы, тем самым значительно снижая накладные расходы на хранение данных с малым числом уникальных значений. Nullable(T) добавляет внутренний битмап к столбцу T, указывая, являются ли значения столбца NULL или нет.
Наконец, таблицы могут быть разбиты на диапазоны, хеши или круговое шардирование с использованием произвольно заданных выражений для партиционирования. Чтобы включить сокращение партиций, ClickHouse дополнительно хранит минимальные и максимальные значения выражения партиционирования для каждой партиции. Пользователи могут по желанию создавать более сложную статистику по столбцам (например, статистику HyperLogLog [30] или t-digest [28]), которые также предоставляют оценки кардинальности.
3.2 Сокращение Данных
В большинстве случаев обход пета-байтов данных всего лишь для ответа на один запрос слишком медленно и дорого. ClickHouse поддерживает три техники сокращения данных, которые позволяют пропустить большинство строк во время поиска и, таким образом, значительно ускорить выполнение запросов.
Во-первых, пользователи могут определить индекс первичного ключа для таблицы. Колонки первичного ключа определяют порядок сортировки строк в каждой части, т.е. индекс локально сгруппирован. ClickHouse дополнительно хранит для каждой части отображение от значений колонок первичного ключа первой строки каждой гранулы к идентификатору гранулы, т.е. индекс является разреженным [31]. В результате структура данных обычно небольшая и остается полностью в памяти, например, для индексирования 8.1 миллиона строк требуется всего 1000 записей. Основная цель первичного ключа - оценивать условия равенства и диапазонов для часто фильтруемых колонок с использованием бинарного поиска вместо последовательных обходов (раздел 4.4). Локальная сортировка также может быть использована для слияний частей и оптимизации запросов, например, для агрегации на основе сортировки или удаления операторов сортировки из физического плана выполнения, когда колонки первичного ключа формируют префикс сортировочных колонок.
Рисунок 4 показывает индекс первичного ключа на колонке EventTime для таблицы со статистикой показов страниц. Гранулы, которые соответствуют диапазону предикта в запросе, могут быть найдены путем бинарного поиска индекса первичного ключа вместо последовательного обхода EventTime.

Рисунок 4: Оценка фильтров с индексом первичного ключа.
Во-вторых, пользователи могут создать проекции таблицы, т.е. альтернативные версии таблицы, которые содержат те же строки, отсортированные по другому первичному ключу [71]. Проекции позволяют ускорить запросы, которые фильтруют по колонкам, отличным от основного первичного ключа таблицы, за счет увеличения накладных расходов на вставки, слияния и потребление пространства. По умолчанию, проекции заполняются лениво только из новых частей, вставленных в основную таблицу, но не из существующих частей, если пользователь не материализует проекцию полностью. Оптимизатор запросов выбирает, исходя из оцененных затрат ввода-вывода, между чтением из основной таблицы и проекции. Если проекции для части не существует, выполнение запроса возвращается к соответствующей части основной таблицы.
В-третьих, индексы пропуска предоставляют легковесную альтернативу проекциям. Идея индексов пропуска заключается в том, чтобы хранить небольшое количество метаданных на уровне нескольких последовательных гранул, что позволяет избежать обхода неактуальных строк. Индексы пропуска могут быть созданы для произвольных выражений индекса и с использованием настраиваемой тонкости, т.е. количества гранул в блоке индекса пропуска. Доступные типы индексов пропуска включают: 1. Индексы min-max [51], хранящие минимальные и максимальные значения для каждого блока индекса. Этот тип индекса хорош для локально сгруппированных данных с небольшими абсолютными диапазонами, например, слабо отсортированных данных. 2. Индексы множеств, хранящие настраиваемое количество уникальных значений блока индекса. Эти индексы лучше всего использовать с данными с небольшой локальной кардинальностью, т.е. "скопленными" значениями. 3. Индексы фильтра Блума [9], построенные для строк, токенов или n-gram значений с настраиваемой вероятностью ложных срабатываний. Эти индексы поддерживают текстовый поиск [73], но, в отличие от индексов min-max и множеств, они не могут быть использованы для диапазонных или отрицательных предикатов.
3.3 Преобразование Данных Времени Слияния
Сценарии бизнес-аналитики и наблюдаемости часто требуют обработки данных, генерируемых с постоянно высокими темпами или всплесками. К тому же, недавно сгенерированные данные, как правило, более актуальны для полезных инсайтов в реальном времени, чем исторические. Такие сценарии требуют от баз данных поддерживать высокие темпы загрузки данных, одновременно сокращая объем исторических данных с помощью таких техник, как агрегация или старение данных. ClickHouse позволяет непрерывно инкрементально трансформировать существующие данные с использованием различных стратегий слияния. Преобразование данных во время слияния не влияет на производительность операторов INSERT, но не может гарантировать, что таблицы никогда не будут содержать нежелательных (например, устаревших или неагрегированных) значений. Если необходимо, все преобразования во время слияния могут быть применены во время выполнения запроса путем указания ключевого слова FINAL в операторе SELECT.
Замещающие слияния сохраняют только последнюю вставленную версию кортежа на основе времени создания ее содержащей части, более старые версии удаляются. Кортежи считаются эквивалентными, если у них одинаковые значения колонок первичного ключа. Для явного контроля над тем, какой кортеж сохранять, также можно указать специальную колонку версии для сравнения. Замещающие слияния обычно используются в качестве механизма обновления во время слияния (обычно в сценариях, где обновления часты) или в качестве альтернативы дедупликации данных во время вставки (раздел 3.5).
Агрегирующие слияния объединяют строки с равными значениями колонок первичного ключа в одну агрегированную строку. Непервичные колонки должны быть в состоянии частичной агрегации, которое хранит сводные значения. Два состояния частичной агрегации, например, сумма и количество для avg(), объединяются в новое состояние частичной агрегации. Агрегирующие слияния обычно используются в материализованных представлениях вместо нормальных таблиц. Материализованные представления заполняются на основе запроса преобразования к исходной таблице. В отличие от других баз данных, ClickHouse не обновляет материализованные представления периодически всем содержимым исходной таблицы. Вместо этого материализованные представления обновляются инкрементально с результатом запроса преобразования, когда новая часть вставляется в исходную таблицу.
Рисунок 5 показывает материализованное представление, определенное на таблице со статистикой показов страниц. Для новых частей, вставленных в исходную таблицу, запрос преобразования вычисляет максимальные и средние задержки, сгруппированные по регионам, и вставляет результат в материализованное представление. Агрегационные функции avg() и max() с расширением -State возвращают состояния частичной агрегации вместо фактических результатов. Агрегирующее слияние, определенное для материализованного представления, непрерывно объединяет частичные состояния агрегации в разных частях. Чтобы получить итоговый результат, пользователи консолидируют частичные состояния агрегации в материализованном представлении с помощью avg() и max() с расширением -Merge.
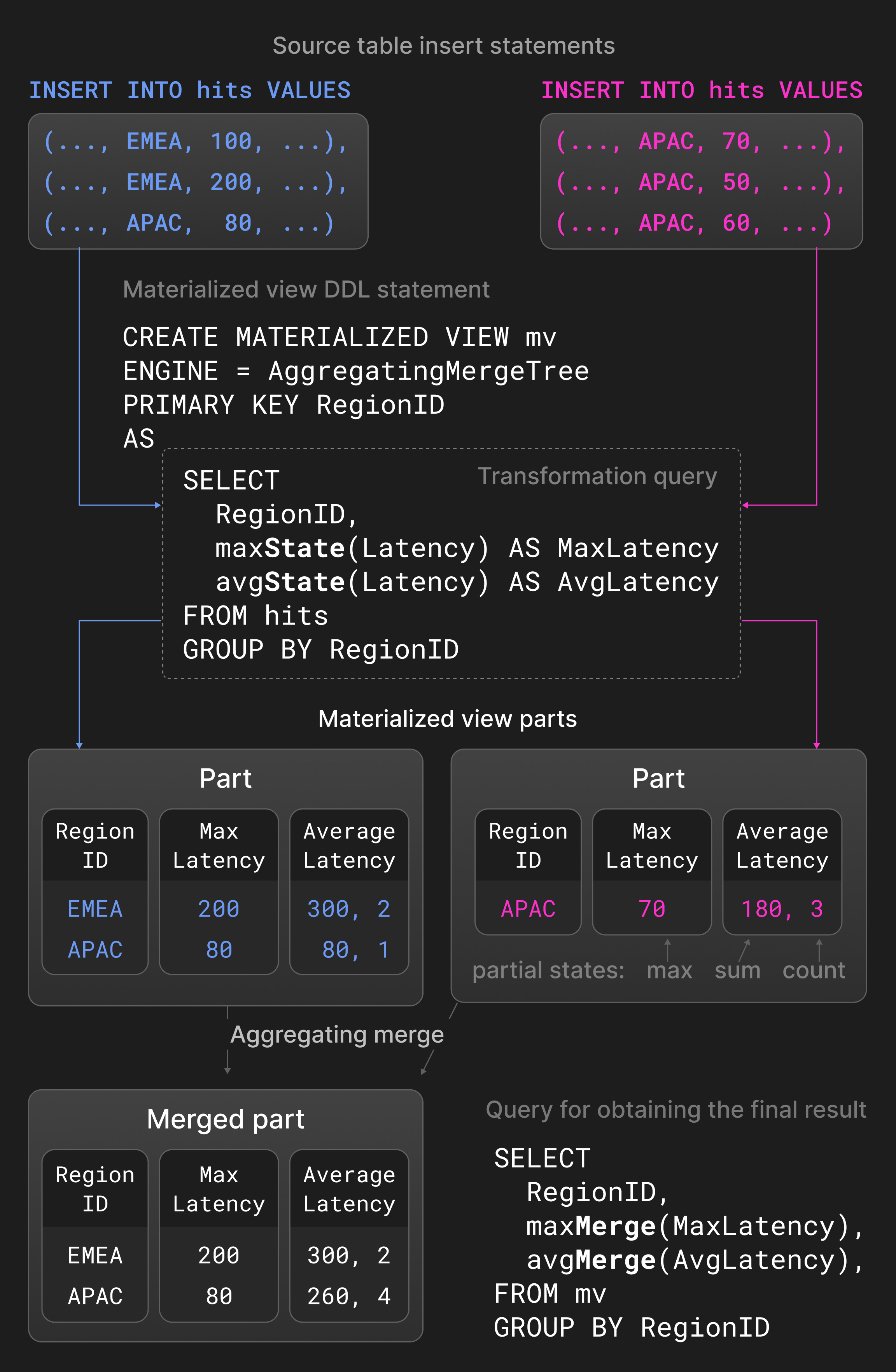
Рисунок 5: Агрегирующие слияния в материализованных представлениях.
TTL (время жизни) слияния обеспечивают старение исторических данных. В отличие от слияний удаления и агрегации, слияния TTL обрабатывают только одну часть за раз. Слияния TTL определяются в терминах правил с триггерами и действиями. Триггер - это выражение, вычисляющее временную метку для каждой строки, которое сравнивается с временем, когда запускается слияние TTL. В то время как это позволяет пользователям контролировать действия на уровне строк, мы обнаружили, что достаточно проверить, удовлетворяют ли все строки данному условию и выполнить действие на всей части. Возможные действия включают в себя 1. перемещение части на другой объем (например, более дешевое и медленное хранилище), 2. повторное сжатие части (например, с использованием более тяжелого кодека), 3. удаление части и 4. сводка, т.е. агрегация строк с использованием ключа группировки и агрегатных функций.
В качестве примера, рассмотрим определение таблицы логов в Списке 1. ClickHouse переместит части со значениями временной колонки старше одной недели в медленное, но недорогое объектное хранилище S3.
Список 1: Переместить часть в объектное хранилище через неделю.
3.4 Обновления и Удаления
Дизайн движков таблиц MergeTree* предпочитает нагрузки только на добавление, однако некоторые случаи использования требуют периодической модификации существующих данных, например, для соблюдения нормативных требований. Существует два подхода для обновления или удаления данных, ни один из которых не блокирует параллельные вставки.
Мутации переписывают все части таблицы на месте. Чтобы предотвратить временное удвоение таблицы (удаление) или колонки (обновление) в размере, эта операция не является атомарной, т.е. параллельные операторы SELECT могут читать мутированные и немутированные части. Мутации гарантируют, что данные физически изменяются в конце операции. Мутации удаления по-прежнему затратные, так как они переписывают все колонки во всех частях.
В качестве альтернативы, легковесные удаления обновляют только внутренний битмап колонны, указывая, удалена ли строка или нет. ClickHouse дополняет запросы SELECT дополнительным фильтром по битмап колонне, чтобы исключить удаленные строки из результата. Физически удаленные строки убираются только регулярными слияниями в неопределенное время будущего. В зависимости от количества колонок, легковесные удаления могут быть значительно быстрее, чем мутации, за счет более медленного выполнения SELECT.
Ожидается, что операции обновления и удаления, выполняемые на одной таблице, будут редкими и сериализованными, чтобы избежать логических конфликтов.
3.5 Идемпотентные Вставки
Проблема, которая часто возникает на практике, заключается в том, как клиенты должны обрабатывать тайм-ауты соединения после отправки данных на сервер для вставки в таблицу. В этой ситуации клиентам сложно различить, были ли данные успешно вставлены или нет. Проблема традиционно решается повторной отправкой данных от клиента на сервер и полаганием на первичный ключ или уникальные ограничения для отклонения дублирующих вставок. Базы данных быстро выполняют необходимые точечные операции поиска с помощью структур индекса на основе бинарных деревьев [39, 68], деревьев радиуса [45] или хеш-таблиц [29]. Поскольку эти структуры данных индексируют каждый кортеж, их затраты на пространство и обновления становятся непомерными для больших наборов данных и высоких темпов загрузки.
ClickHouse предоставляет более легковесную альтернативу, основанную на том, что каждая вставка в конечном итоге создает часть. Более конкретно, сервер поддерживает хеши N последних вставленных частей (например, N=100) и игнорирует повторные вставки частей с известным хешем. Хеши для нереплицированных и реплицированных таблиц хранятся локально, соответственно, в Keeper. В результате вставки становятся идемпотентными, т.е. клиенты могут просто повторно отправить тот же пакет строк после тайм-аута и предположить, что сервер позаботится о дедупликации. Для большего контроля над процессом дедупликации клиенты могут дополнительно предоставить токен вставки, который действует как хеш части. Хотя дедупликация на основе хеша влечет за собой накладные расходы, связанные с хешированием новых строк, стоимость хранения и сравнения хешей является незначительной.
3.6 Репликация Данных
Репликация является предпосылкой для высокой доступности (устойчивости к сбоям узлов), но также используется для балансировки нагрузки и обновлений без времени простоя [14]. В ClickHouse репликация основывается на понятии состояний таблиц, которые состоят из набора частей таблиц (Раздел 3.1) и метаданных таблицы, таких как имена и типы колонок. Узлы обновляют состояние таблицы с помощью трех операций: 1. Вставки добавляют новую часть в состояние, 2. слияния добавляют новую часть и удаляют существующие части из состояния, 3. мутации и DDL операторы добавляют части, и/или удаляют части, и/или изменяют метаданные таблицы, в зависимости от конкретной операции. Операции выполняются локально на одном узле и записываются как последовательность переходов состояния в глобальный журнал репликации.
Журнал репликации поддерживается ансамблем из обычно трех процессов ClickHouse Keeper, которые используют алгоритм консенсуса Raft [59] для предоставления распределенного и отказоустойчивого координационного слоя для кластера узлов ClickHouse. Все узлы кластера изначально указывают на одно и то же положение в журнале репликации. Пока узлы выполняют локальные вставки, слияния, мутации и DDL операторы, журнал репликации воспроизводится асинхронно на всех других узлах. В результате, реплицированные таблицы являются лишь в конечном итоге консистентными, т.е. узлы могут временно считывать старые состояния таблицы, пока они стремятся к последнему состоянию. Большинство из вышеупомянутых операций также могут выполняться синхронно до тех пор, пока кворум узлов (например, большинство узлов или все узлы) не примет новое состояние.
В качестве примера, Рисунок 6 показывает изначально пустую реплицированную таблицу в кластере из трех узлов ClickHouse. Узел 1 сначала получает два оператора вставки и записывает их ( 1 2 ) в журнал репликации, хранящийся в ансамбле Keeper. Затем Узел 2 воспроизводит первую запись журнала, получая ее ( 3 ) и загружая новую часть с Узла 1 ( 4 ), в то время как Узел 3 воспроизводит обе записи журнала ( 3 4 5 6 ). Наконец, Узел 3 объединяет обе части в новую часть, удаляет исходные части и записывает запись слияния в журнал репликации ( 7 ).
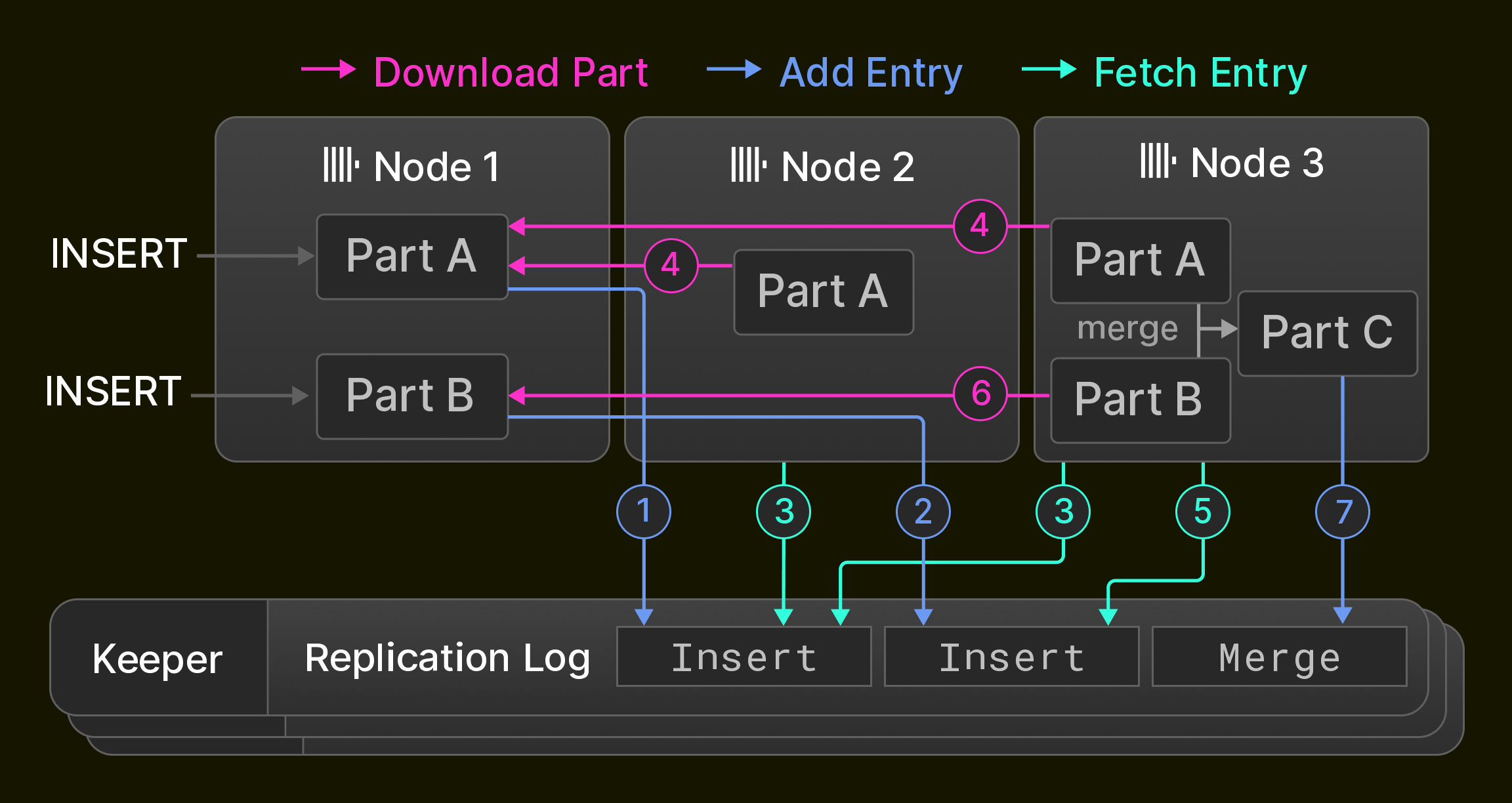
Рисунок 6: Репликация в кластере из трех узлов.
Существуют три оптимизации для ускорения синхронизации: Во-первых, новые узлы, добавленные в кластер, не воспроизводят журнал репликации с нуля, вместо этого они просто копируют состояние узла, который записал последнюю запись в журнале репликации. Во-вторых, слияния воспроизводятся, либо повторяя их локально, либо извлекая результирующую часть с другого узла. Точное поведение настраивается и позволяет сбалансировать потребление CPU и ввод-вывод сети. Например, репликация между дата-центрами обычно предпочитает локальные слияния, чтобы минимизировать операционные расходы. В-третьих, узлы воспроизводят взаимно независимые записи журнала репликации параллельно. Это включает, например, получение новых частей, вставленных последовательно в одну и ту же таблицу, или операции с разными таблицами.
3.7 Соответствие ACID
Чтобы максимизировать производительность одновременных операций чтения и записи, ClickHouse избегает блокировок насколько это возможно. Запросы выполняются на снимке всех частей во всех вовлеченных таблицах, созданном в начале запроса. Это гарантирует, что новые части, вставленные параллельными INSERT или слияниями (Раздел 3.1), не участвуют в выполнении. Чтобы предотвратить одновременное изменение или удаление частей (Раздел 3.4), счетчик ссылок на обрабатываемые части увеличивается на время выполнения запроса. Формально это соответствует изоляции снимков, реализованной с помощью варианта MVCC [6], основанного на версионированных частях. В результате, операторы обычно не соответствуют ACID, за исключением редкого случая, когда одновременные записи в момент создания снимка затрагивают лишь одну часть.
На практике, большинство сценариев принятия решений в ClickHouse, связанных с частыми записями, даже допускают небольшой риск потери новых данных в случае отключения питания. База данных использует это, не заставляя выполнять коммит (fsync) вновь вставленных частей на диск по умолчанию, позволяя ядру объединять записи с ценой отказа от атомарности.
4 УРОВЕНЬ ОБРАБОТКИ ЗАПРОСОВ
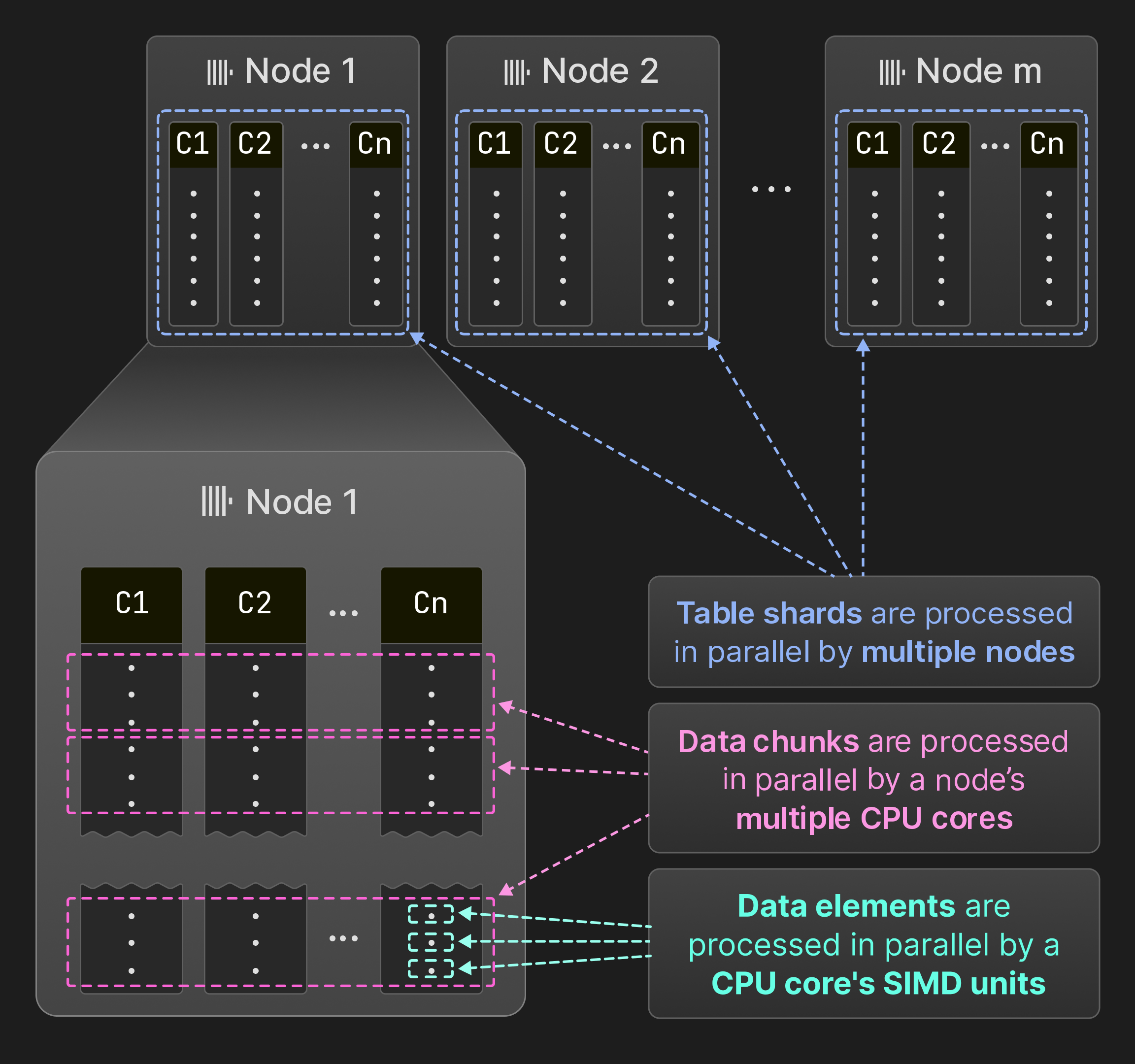
Рисунок 7: Параллелизация по единицам SIMD, ядрам и узлам.
Как показано на Рисунке 7, ClickHouse параллелизует запросы на уровне элементов данных, пакетах данных и шардов таблиц. Несколько элементов данных могут обрабатываться внутри операторов одновременно, используя инструкции SIMD. На одном узле движок запросов выполняет операции одновременно в нескольких потоках. ClickHouse использует ту же модель векторизации, что и MonetDB/X100 [11], т.е. операторы генерируют, передают и потребляют несколько строк (пакетов данных) вместо отдельных строк, чтобы минимизировать накладные расходы на виртуальные вызовы функций. Если исходная таблица разбита на раздельные шардные таблицы, несколько узлов могут одновременно сканировать шардные таблицы. В результате все аппаратные ресурсы полностью используются, а обработка запросов может быть горизонтально масштабирована за счет добавления узлов и вертикально за счет увеличения числа ядер.
Остальная часть этого раздела сначала описывает параллельную обработку на уровне элементов данных, пакетах данных и шардов более подробно. Затем мы представим избранные ключевые оптимизации для максимизации производительности запросов. Наконец, мы обсудим, как ClickHouse управляет общими системными ресурсами в условиях одновременных запросов.
4.1 Параллелизация SIMD
Передача нескольких строк между операторами создает возможность для векторизации. Векторизация основана либо на вручную написанных встроенных функциях [64, 80], либо на авто-векторизации компилятора [25]. Код, который выигрывает от векторизации, компилируется в различные вычислительные ядра. Например, внутренний "горячий" цикл оператора запроса может быть реализован в терминах невекторизованного ядра, авто-векторизованного ядра AVX2 и вручную векторизованного ядра AVX-512. Самое быстрое ядро выбирается во время выполнения на основе инструкции cpuid. Этот подход позволяет ClickHouse работать на системах возрастом до 15 лет (требуя SSE 4.2 как минимум), обеспечивая при этом значительное ускорение на современном оборудовании.
4.2 Параллелизация Многопоточности
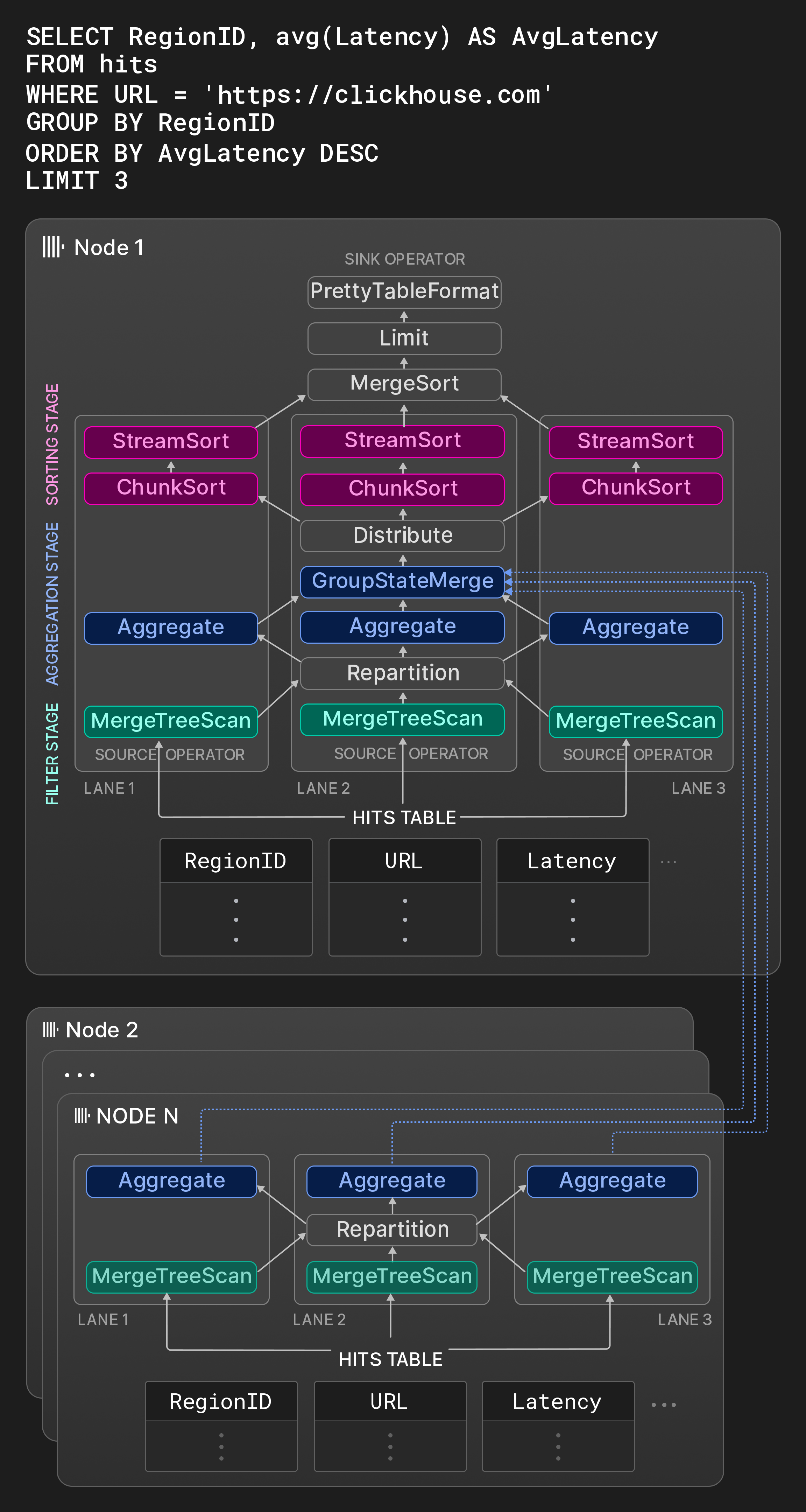
Рисунок 8: Физический оперирующий план с тремя дорожками.
ClickHouse следует обычному подходу [31] преобразования SQL-запросов в направленный граф физических операторов. Вход операторного плана представлен специальными источниками, которые читают данные в их исходном или любом из поддерживаемых сторонних форматов (см. Раздел 5). Аналогично, специальный оператор-сток преобразует результат в желаемый выходной формат. Физический операторный план разворачивается во время компиляции запроса в независимые исполняемые дорожки на основе настраиваемого максимального числа рабочих потоков (по умолчанию — число ядер) и размера исходной таблицы. Дорожки разбивают данные, которые должны быть обработаны параллельными операторами, на неперекрывающиеся диапазоны. Чтобы максимально использовать возможности параллельной обработки, дорожки объединяются как можно позднее.
В качестве примера, область для Узла 1 на Рисунке 8 показывает граф операторов типичного OLAP-запроса к таблице со статистикой показов страниц. На первом этапе три раздельных диапазона исходной таблицы фильтруются одновременно. Оператор обмена Repartition динамически маршрутизирует результаты между первым и вторым этапами, чтобы поддерживать равномерную загрузку потоков обработки. Дорожки могут стать несбалансированными после первого этапа, если отсканированные диапазоны имеют значительно разные селективности. На втором этапе строки, которые прошли через фильтр, группируются по RegionID. Операторы Aggregate поддерживают локальные группы результатов с RegionID в качестве колонки группировки и сумму и количество по группе в качестве частичного состояния агрегации для avg(). Локальные результаты агрегации в конечном итоге объединяются оператором GroupStateMerge в глобальный результат агрегации. Этот оператор также является разрывом в конвейере, т.е. третий этап может начаться только после того, как результат агрегации полностью вычислен. На третьем этапе группы результатов сначала разделяются оператором обмена Distribute на три равные неперекрывающиеся партиции, которые затем сортируются по AvgLatency. Сортировка выполняется в три этапа: во-первых, операторы ChunkSort сортируют отдельные пакеты каждой партиции. Во-вторых, операторы StreamSort поддерживают локальный отсортированный результат, который комбинируется с входящими отсортированными пакетами, используя 2-way merge сортировку. Наконец, оператор MergeSort объединяет локальные результаты, используя k-way сортировку, чтобы получить конечный результат.
Операторы представляют собой конечные автоматы и соединены друг с другом через входные и выходные порты. Три возможные состояния оператора — need-chunk, ready и done. Чтобы перейти от need-chunk к ready, пакет помещается в входной порт оператора. Чтобы перейти от ready к done, оператор обрабатывает входящий пакет и генерирует выходной пакет. Чтобы перейти от done к need-chunk, выходной пакет удаляется из выходного порта оператора. Первые и третьи переходы состояния в двух связанных операторах могут выполняться только в комбинированном шаге. Исходные операторы (операторы-стоки) имеют только состояния ready и done (need-chunk и done).
Рабочие потоки непрерывно проходят физический операторный план и выполняют переходы состояния. Чтобы поддерживать "горячими" кэши CPU, план содержит подсказки о том, что один и тот же поток должен обрабатывать последовательные операторы в одной дорожке. Параллельная обработка происходит как горизонтально по раздельным входам в пределах этапа (например, на Рисунке 8 операторы Aggregate выполняются одновременно), так и вертикально между этапами, которые не разделены разрывами в конвейере (например, на Рисунке 8 оператор фильтрации и оператор агрегации в одной дорожке могут работать одновременно). Чтобы избежать избыточной и недогруженной подписки, когда начинаются новые запросы или одновременно заканчиваются текущие запросы, степень параллелизма можно изменить во время выполнения запроса между одним и максимальным числом рабочих потоков для запроса, указанного в начале запроса (см. Раздел 4.5).
Операторы могут дополнительно влиять на выполнение запроса во время выполнения двумя способами. Во-первых, операторы могут динамически создавать и соединять новые операторы. Это в основном используется для переключения на внешние алгоритмы агрегации, сортировки или соединения, вместо отмены запроса, когда потребление памяти превышает настраиваемый предел. Во-вторых, операторы могут запрашивать рабочие потоки о переходе в асинхронную очередь. Это обеспечивает более эффективное использование рабочих потоков при ожидании удаленных данных.
Движок выполнения запросов ClickHouse и параллелизм, основанный на порциях [44], схожи тем, что дорожки обычно выполняются на разных ядрах / NUMA сокетах и рабочие потоки могут красть задачи у других дорожек. Также нет центрального компонента планирования; вместо этого рабочие потоки индивидуально выбирают свои задачи, непрерывно проходя по плану операторов. В отличие от параллелизма, основанного на порциях, ClickHouse закладывает максимальную степень параллелизма в план и использует гораздо большие диапазоны для разделения исходной таблицы по сравнению с размерами стандартных порций примерно 100.000 строк. Хотя это может в некоторых случаях вызывать задержки (например, когда время выполнения операторов фильтрации в разных дорожках сильно отличается), мы обнаружили, что активное использование операторов обмена, таких как Repartition, по крайней мере, предотвращает накопление таких несоответствий между этапами.
4.3 Параллелизация на нескольких узлах
Если исходная таблица запроса шардирована, оптимизатор запросов на узле, который получил запрос (инициирующий узел), пытается выполнить как можно больше работы на других узлах. Результаты с других узлов могут быть интегрированы в различные точки плана запроса. В зависимости от запроса удаленные узлы могут либо 1. передавать необработанные столбцы исходной таблицы на инициирующий узел, 2. фильтровать исходные столбцы и отправлять оставшиеся строки, 3. выполнять фильтрацию и агрегацию и отправлять локальные группы результатов с частичными состояниями агрегации, либо 4. выполнять весь запрос, включая фильтрацию, агрегацию и сортировку.
Узел 2 ... N на Рисунке 8 показывает фрагменты плана, выполняемые на других узлах, содержащих шарды таблицы хитов. Эти узлы фильтруют и группируют локальные данные и отправляют результаты на инициирующий узел. Оператор GroupStateMerge на узле 1 объединяет локальные и удаленные результаты перед тем, как группы результатов в конечном итоге сортируются.
4.4 Холистическая Оптимизация Производительности
В этом разделе представлены избранные ключевые оптимизации производительности, применяемые на различных этапах выполнения запросов.
Оптимизация запроса. Первый набор оптимизаций применяется на основе семантического представления запроса, полученного из AST запроса. Примеры таких оптимизаций включают сведение констант (например, concat(lower('a'),upper('b')) становится 'aB'), извлечение скалярных значений из определенных агрегатных функций (например, sum(a2) становится 2 * sum(a)), устранение общих подвыражений и преобразование дизъюнкций равенств фильтров в списки IN (например, x=c OR x=d становится x IN (c,d)). Оптимизированное семантическое представление запроса затем преобразуется в логический операторный план. Оптимизации, применяемые к логическому плану, включают продвижение фильтров, перестановку вычислений функций и шагов сортировки в зависимости от того, какая из них оценивается как более дорогая. Наконец, логический запросный план преобразуется в физический операторный план. Это преобразование может использовать особенности вовлеченных движков таблиц. Например, в случае движка таблиц MergeTree, если колонки ORDER BY формируют префикс первичного ключа, данные могут быть прочитаны в дисковом порядке, и операторы сортировки могут быть удалены из плана. Также, если колонки группировки в агрегации формируют префикс первичного ключа, ClickHouse может использовать сортировочную агрегацию [33], т.е. агрегировать последовательности одно и то же значения в предварительно отсортированных входных данных напрямую. По сравнению с хеш-агрегацией, сортировочная агрегация требует значительно меньшего объема памяти, и агрегированное значение может быть передано следующему оператору сразу после обработки последовательности.
Компиляция запроса. ClickHouse использует компиляцию запросов на основе LLVM для динамического объединения смежных операторов плана [38, 53]. Например, выражение a * b + c + 1 может быть объединено в один оператор вместо трех операторов. Помимо выражений, ClickHouse также использует компиляцию для одновременной оценки нескольких агрегатных функций (т.е. для GROUP BY) и для сортировки с более чем одним ключом сортировки. Компиляция запросов уменьшает количество виртуальных вызовов, держит данные в регистрах или кэше CPU и помогает предсказателю ветвлений, так как требуется выполнить меньше кода. Кроме того, компиляция во время выполнения позволяет реализовать богатый набор оптимизаций, таких как логические оптимизации и оптимизации в пределах окна, реализованные в компиляторах, и предоставляет доступ к самым быстрым доступным инструкциям CPU. Компиляция инициируется только в том случае, если одно и то же регулярное, агрегатное или сортировочное выражение выполняется различными запросами более чем определенное количество раз. Скомпилированные операторы запросов кэшируются и могут быть повторно использованы будущими запросами.[7]
Оценка первичного индекса ключа. ClickHouse оценивает условия WHERE с помощью первичного индекса ключа, если подмножество условий фильтрации в конъюнктивной нормальной форме составляет префикс первичных ключевых колонок. Первичный индекс ключа анализируется слева направо по лексикографически упорядоченным диапазонам значений ключа. Условия фильтрации, соответствующие колонке первичного ключа, оцениваются с использованием тернарной логики — они все истинны, все ложны или смешаны для значений в диапазоне. В последнем случае диапазон делится на поддиапазоны, которые анализируются рекурсивно. Существуют и дополнительные оптимизации для функций в условиях фильтрации. Во-первых, функции имеют характеристики, описывающие их монотонность, например, toDayOfMonth(date) является кусочно монотонным в пределах одного месяца. Характеристики монотонности позволяют сделать вывод, производит ли функция отсортированные результаты по отсортированным диапазонам значений ключа. Во-вторых, некоторые функции могут вычислить прообраз данного результата функции. Это используется для замены сравнений констант с вызовами функций по ключевым колонкам, сравнивая значение ключевой колонки с прообразом. Например, toYear(k) = 2024 может быть заменено на k >= 2024-01-01 && k < 2025-01-01.
Пропуск данных. ClickHouse старается избежать чтения данных во время выполнения запроса, используя структуры данных, представленные в Разделе 3.2. Кроме того, фильтры на разных колонках оцениваются последовательно в порядке убывания оцененной селективности, основанной на эвристиках и (опциональной) статистике колонок. Только пакеты данных, содержащие хотя бы одну подходящую строку, передаются к следующему предикату. Это постепенно уменьшает количество прочитанных данных и количество вычислений, которые необходимо выполнить от предиката к предикату. Оптимизация применяется только тогда, когда присутствует хотя бы один сильно селективный предикат; в противном случае задержка запроса ухудшалась бы по сравнению с оценкой всех предикатов параллельно.
Хеш-таблицы. Хеш-таблицы являются основными структурами данных для агрегации и хеш-соединений. Выбор правильного типа хеш-таблицы критичен для производительности. ClickHouse создает различные хеш-таблицы (более 30 на март 2024) на основе общего шаблона хеш-таблицы с функцией хеширования, аллокатором, типом ячейки и политикой изменения размера как вариативные точки. В зависимости от типа данных колонок группировки, оценочной кардинальности хеш-таблицы и других факторов, для каждого оператора запроса индивидуально выбирается самая быстрая хеш-таблица. Дополнительные оптимизации, реализованные для хеш-таблиц, включают:
- двухуровневую компоновку с 256 подтаблицами (на основе первого байта хеша) для поддержки огромных наборов ключей,
- строковые хеш-таблицы [79] с четырьмя подтаблицами и различными функциями хеширования для различных длин строк,
- таблицы поиска, которые используют ключ непосредственно как индекс корзины (т.е. без хеширования), когда ключей немного,
- значения с встроенными хешами для ускоренного разрешения коллизий, когда сравнение является дорогостоящим (например, строки, AST),
- создание хеш-таблиц на основе предсказанных размеров из статистики выполнения, чтобы избежать ненужных изменений размера,
- аллокация нескольких небольших хеш-таблиц с одинаковым циклом создания/удаления на одном слое памяти,
- мгновенное очищение хеш-таблиц для повторного использования с использованием подсчетчиков версий по каждой таблице хешей и по каждой ячейке,
- использование предварительной выборки CPU (__builtin_prefetch) для ускорения получения значений после хеширования ключа.
Соединения. Поскольку изначально ClickHouse поддерживал соединения лишь в rudimentary виде, многие сценарии исторически обращались к денормализованным таблицам. Сегодня база данных предлагает все типы соединений, доступные в SQL (внутренние, левые/правые/полные внешние, перекрестные, as-of), а также различные алгоритмы соединений, такие как хеш-соединение (наивное, grace), соединение сортировки и соединение индекса для движков таблиц с быстрым поиском ключ-значение (обычно словарями).
Поскольку соединения являются одними из самых дорогостоящих операций в базах данных, важно предоставить параллельные варианты классических алгоритмов соединений, желательно с настраиваемыми компромиссами между пространством и временем. Для хеш-соединений ClickHouse реализует неблокирующий, общий алгоритм разделов из [7]. Например, запрос на Рисунке 9 вычисляет, как пользователи перемещаются между URL-адресами через само-соединение на таблице статистики показов страниц. Фаза построения соединения делится на три дорожки, охватывающие три раздельных диапазона исходной таблицы. Вместо глобальной хеш-таблицы используется разделенная хеш-таблица. (обычно три) рабочих потока определяют целевую часть для каждой входной строки стороны построения, вычисляя модуль функции хеширования. Доступ к разделам хеш-таблицы синхронизируется с помощью операторов обмена Gather. Фаза проверки находит целевую часть своих входных кортежей аналогично. Хотя этот алгоритм вводит два дополнительных вычисления хеширования на пару, он значительно уменьшает конкуренцию за блокировки на этапе построения, в зависимости от количества разделов хеш-таблицы.
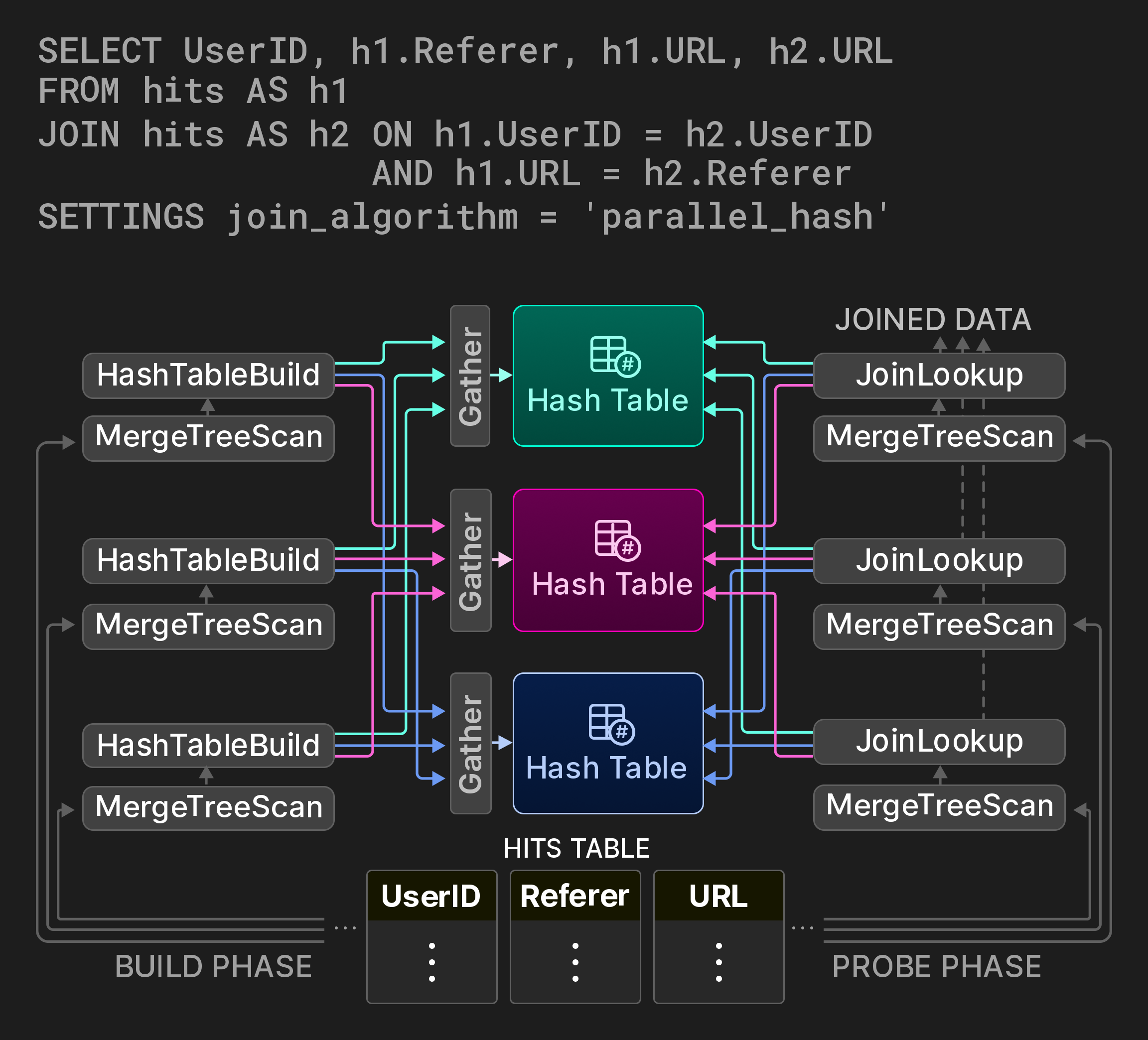
Рисунок 9: Параллельное хеш-соединение с тремя разделами хеш-таблицы.
4.5 Изоляция Нагрузки
ClickHouse предлагает управление параллелизмом, ограничения на использование памяти и планирование I/O, позволяя пользователям изолировать запросы в классы нагрузки. Устанавливая лимиты на общие ресурсы (ядра CPU, DRAM, диск и сетевой ввод-вывод) для конкретных классов нагрузки, система гарантирует, что эти запросы не повлияют на другие критические бизнес-запросы.
Управление параллелизмом предотвращает избыточную подписку потоков в сценариях с высоким числом параллельных запросов. Более конкретно, количество рабочих потоков на запрос динамически регулируется на основе заданного соотношения к количеству доступных ядер CPU.
ClickHouse отслеживает объем памяти на серверном, пользовательском и запросном уровнях, позволяя устанавливать гибкие лимиты использования памяти. Переизбыток памяти позволяет запросам использовать дополнительную свободную память сверх гарантированной, при этом обеспечивая лимиты памяти для других запросов. Кроме того, использование памяти для агрегации, сортировки и условий соединения может быть ограничено, что приводит к переходу к внешним алгоритмам при превышении лимита памяти.
Наконец, планирование I/O позволяет пользователям ограничивать локальный и удаленный доступ к дискам для классов нагрузки на основе максимальной пропускной способности, текущих запросов и политики (например, FIFO, SFC [32]).
5 УРОВЕНЬ ИНТЕГРАЦИИ
Приложения для принятия решений в реальном времени часто зависят от эффективного и низколатентного доступа к данным из нескольких мест. Существуют два подхода для обеспечения доступности внешних данных в OLAP базе данных. С помощью доступа на основе выталкивания, компонент третьей стороны соединяет базу данных с внешними хранилищами данных. Одним из примеров являются специализированные инструменты извлечения, преобразования и загрузки (ETL), которые передают удаленные данные в целевую систему. В модели на основе вытягивания сама база данных подключается к удаленным источникам данных и извлекает данные для запроса в локальные таблицы или экспортирует данные в удаленные системы. Хотя подходы на основе вытягивания более универсальны и распространены, они имеют более крупный архитектурный след и узкие места масштабируемости. В отличие от этого, удаленная связь непосредственно в базе данных предлагает интересные возможности, такие как соединения между локальными и удаленными данными, при этом сохраняя общую архитектуру простой и уменьшая время для получения результатов.
Остальная часть раздела исследует методы интеграции данных на основе вытягивания в ClickHouse, направленные на доступ к данным в удаленных местах. Мы отмечаем, что идея удаленной связи в SQL базах данных не является новой. Например, стандарт SQL/MED [35], введенный в 2001 году и реализованный PostgreSQL с 2011 года [65], предлагает внешние оболочки данных как единый интерфейс для управления внешними данными. Максимальная совместимость с другими хранилищами данных и форматами хранения является одной из целей дизайна ClickHouse. По состоянию на март 2024 года ClickHouse предлагает, насколько нам известно, наиболее встроенные варианты интеграции данных среди всех аналитических баз данных.
Внешняя Связь. ClickHouse предоставляет более 50 интеграционных табличных функций и движков для связи с внешними системами и местами хранения, включая ODBC, MySQL, PostgreSQL, SQLite, Kafka, Hive, MongoDB, Redis, S3/GCP/Azure объектные хранилища и различные озера данных. Мы дополнительно разбиваем их на категории, показанные на следующем бонусном рисунке (не часть оригинальной статьи vldb).
Бонусный Рисунок: Варианты взаимодействия ClickBench.
Временный доступ с помощью интеграционных табличных функций. Табличные функции могут быть вызваны в клаузе FROM запросов SELECT для чтения удаленных данных для исследовательских ad-hoc запросов. В качестве альтернативы, они могут быть использованы для записи данных в удаленные хранилища с помощью операторов INSERT INTO TABLE FUNCTION.
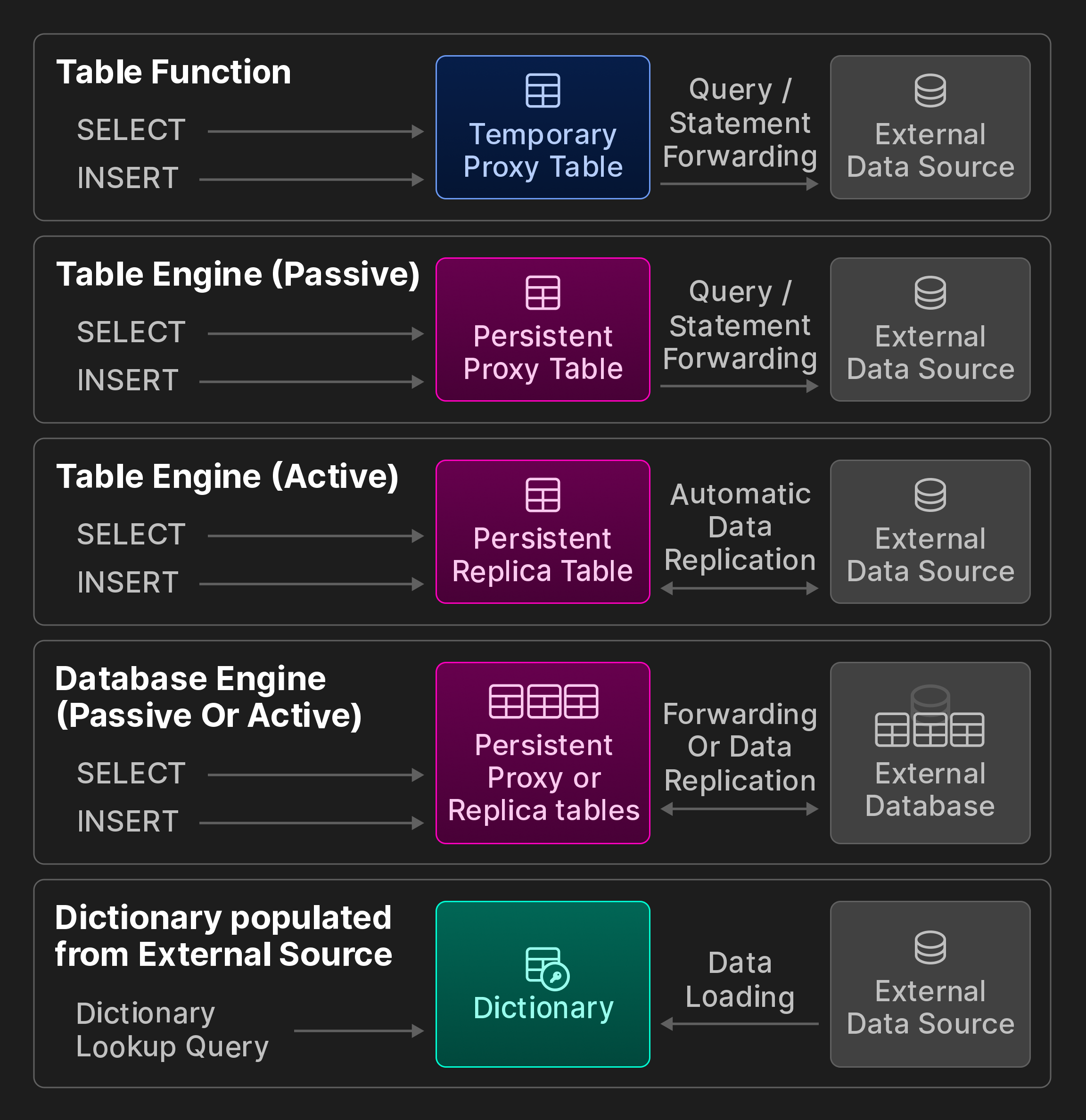
Постоянный доступ. Существуют три метода для создания постоянных соединений с удаленными хранилищами данных и системами обработки.
Во-первых, интеграционные движки таблиц представляют собой удаленный источник данных, такой как таблица MySQL, как постоянную локальную таблицу. Пользователи хранят определение таблицы, используя синтаксис CREATE TABLE AS, в сочетании с запросом SELECT и табличной функцией. Возможна спецификация пользовательской схемы, например, чтобы ссылаться только на подмножество удаленных колонок, или использовать вывод схемы для автоматического определения имен колонок и соответствующих типов ClickHouse. Мы дополнительно различаем пассивное и активное поведение во время выполнения: Пассивные движки таблиц перенаправляют запросы в удаленную систему и заполняют локальную прокси-таблицу результатами. В отличие от этого, активные движки таблиц периодически извлекают данные из удаленной системы или подписываются на удаленные изменения, например, через логическую репликацию PostgreSQL. В результате локальная таблица содержит полную копию удаленной таблицы.
Во-вторых, интеграционные движки баз данных отображают все таблицы схемы таблицы в удаленном хранилище данных в ClickHouse. В отличие от первых, они, как правило, требуют удаленное хранилище данных быть реляционной базой данных и дополнительно предоставляют ограниченную поддержку операторов DDL.
В-третьих, словарь может быть заполнен с помощью произвольных запросов к почти всем возможным источникам данных с соответствующей интеграционной табличной функцией или движком. Поведение во время выполнения активно, так как данные извлекаются с постоянными интервалами из удаленного хранилища.
Форматы Данных. Для взаимодействия с системами сторонних производителей современные аналитические базы данных также должны иметь возможность обрабатывать данные в любом формате. Кроме своих нативных форматов, ClickHouse поддерживает более 90 форматов, включая CSV, JSON, Parquet, Avro, ORC, Arrow и Protobuf. Каждый формат может быть форматом ввода (который ClickHouse может читать), выходным форматом (который ClickHouse может экспортировать) или обоими. Некоторые форматы, ориентированные на аналитику, такие как Parquet, также интегрированы с обработкой запросов, т.е. оптимизатор может использовать встроенную статистику, а фильтры оцениваются непосредственно на сжатых данных.
Совместимые интерфейсы. Помимо своего нативного бинарного wire-протокола и HTTP, клиенты могут взаимодействовать с ClickHouse через совместимые интерфейсы wire-протоколов MySQL или PostgreSQL. Эта функция совместимости полезна для обеспечения доступа из проприетарных приложений (например, некоторые инструменты бизнес-аналитики), где поставщики еще не реализовали нативное соединение ClickHouse.
6 ПРОИЗВОДИТЕЛЬНОСТЬ КАК ФУНКЦИЯ
В этом разделе представлены встроенные инструменты для анализа производительности и оценивается производительность с использованием реальных и бенчмарковых запросов.
6.1 Встроенные Инструменты анализа производительности
Доступно множество инструментов для расследования узких мест производительности в отдельных запросах или фоновых операциях. Пользователи взаимодействуют со всеми инструментами через единый интерфейс на основе системных таблиц.
Статистика сервера и запросов. Статистика уровня сервера, такая как количество активных частей, пропускная способность сети и коэффициенты попаданий в кэш, дополняются статистикой по запросам, такой как количество прочитанных блоков или статистика использования индексов. Метрики рассчитываются синхронно (по запросу) или асинхронно с настраиваемыми интервалами.
Профайлер выборки. Стек вызовов потоков сервера можно собирать с помощью профайлера выборки. Результаты могут быть дополнительно экспортированы во внешние инструменты, такие как визуализаторы flamegraph.
Интеграция OpenTelemetry. OpenTelemetry — это открытый стандарт для трассировки строк данных через несколько систем обработки данных [8]. ClickHouse может генерировать временные промежутки OpenTelemetry с настраиваемой детализацией для всех шагов обработки запросов, а также собирать и анализировать временные промежутки OpenTelemetry из других систем.
Объяснение запроса. Как и в других базах данных, запросы SELECT могут предшествовать EXPLAIN для подробных сведений о AST запроса, логических и физических планах операторов и поведении во время выполнения.
6.2 Бенчмарки
Хотя бенчмарки подвергались критике за недостаточную реалистичность [10, 52, 66, 74], они все еще полезны для выявления сильных и слабых сторон баз данных. В дальнейшем мы обсудим, как бенчмарки используются для оценки производительности ClickHouse.
6.2.1 Денормализованные таблицы
Фильтрация и агрегация запросов к денормализованным фактическим таблицам исторически представляют собой основной случай использования ClickHouse. Мы сообщаем время выполнения ClickBench, типичной нагрузки этого рода, которая моделирует ad-hoc и периодические запросы отчетов, используемые в анализе кликстрима и трафика. Бенчмарк состоит из 43 запросов к таблице с 100 миллионами анонимизированных посещений страниц, полученных от одной из крупнейших аналитических платформ в интернете. Онлайн панель инструментов [17] показывает измерения (холодное/горячее время выполнения, время импорта данных, размер на диске) для более 45 коммерческих и исследовательских баз данных на июнь 2024 года. Результаты предоставляются независимыми авторами на основе общедоступного набора данных и запросов [16]. Запросы тестируют последовательные и индексные пути доступа и постоянно выявляют операторы реляционной базы данных, ограниченные CPU, I/O или памятью.
Рисунок 10 показывает общее относительное холодное и горячее время выполнения для последовательного выполнения всех запросов ClickBench в базах данных, часто используемых для аналитики. Измерения были проведены на однонодовом экземпляре AWS EC2 c6a.4xlarge с 16 vCPUs, 32 ГБ RAM и 5000 IOPS / 1000 MiB/s диска. Сравнимые системы использовались для Redshift (ra3.4xlarge, 12 vCPUs, 96 ГБ RAM) и Snowfake (размер склада S: 2x8 vCPUs, 2x16 ГБ RAM). Физический дизайн базы данных настроен лишь слегка, например, мы указываем первичные ключи, но не изменяем сжатие отдельных колонок, не создаем проекции или индексы пропуска. Мы также очищаем кэш страниц Linux перед каждым запуском холодного запроса, но не настраиваем параметры базы данных или операционной системы. Для каждого запроса используется наименьшее время выполнения среди баз данных в качестве базового. Относительное время выполнения запросов для других баз данных рассчитывается как ( + 10)/(_ + 10). Общее относительное время выполнения для базы данных является геометрическим средним отношений по запросам. Хотя исследовательская база данных Umbra [54] достигает лучшего общего горячего времени выполнения, ClickHouse превосходит все другие базы данных коммерческого уровня по горячему и холодному времени выполнения.
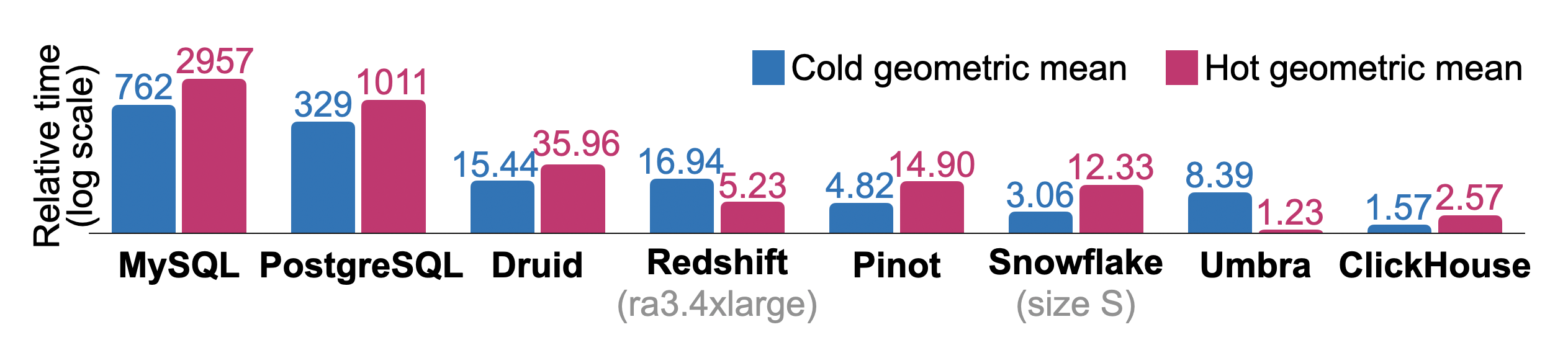
Рисунок 10: Относительное холодное и горячее время выполнения ClickBench.
Чтобы отслеживать производительность SELECT-запросов в более разнообразных рабочих нагрузках с течением времени, мы используем комбинацию четырех бенчмарков под названием VersionsBench [19]. Этот бенчмарк выполняется раз в месяц, когда публикуется новое обновление, чтобы оценить его производительность [20] и идентифицировать изменения в коде, которые потенциально ухудшили производительность: В индивидуальные бенчмарки входят: 1. ClickBench (описанный выше), 2. 15 запросов MgBench [21], 3. 13 запросов к денормализованной Star Schema Benchmark [57] фактической таблице с 600 миллионами строк. 4. 4 запроса к NYC Taxi Rides с 3.4 миллиарда строк [70].
Рисунок 11 показывает развитие времени выполнения VersionsBench для 77 версий ClickHouse с марта 2018 года по март 2024 года. Чтобы компенсировать различия в относительном времени выполнения отдельных запросов, мы нормализуем время выполнения, используя геометрическое среднее с отношением к минимальному времени выполнения запроса среди всех версий в качестве веса. Производительность VersionBench улучшилась в 1.72 раза за последние шесть лет. Даты для релизов с долгосрочной поддержкой (LTS) отмечены на оси X. Хотя производительность временно ухудшалась в некоторые периоды, версии LTS, как правило, имеют сопоставимую или лучшую производительность по сравнению с предыдущей версией LTS. Значительное улучшение в августе 2022 года было вызвано техникой оценки фильтров по колонкам, описанной в разделе 4.4.
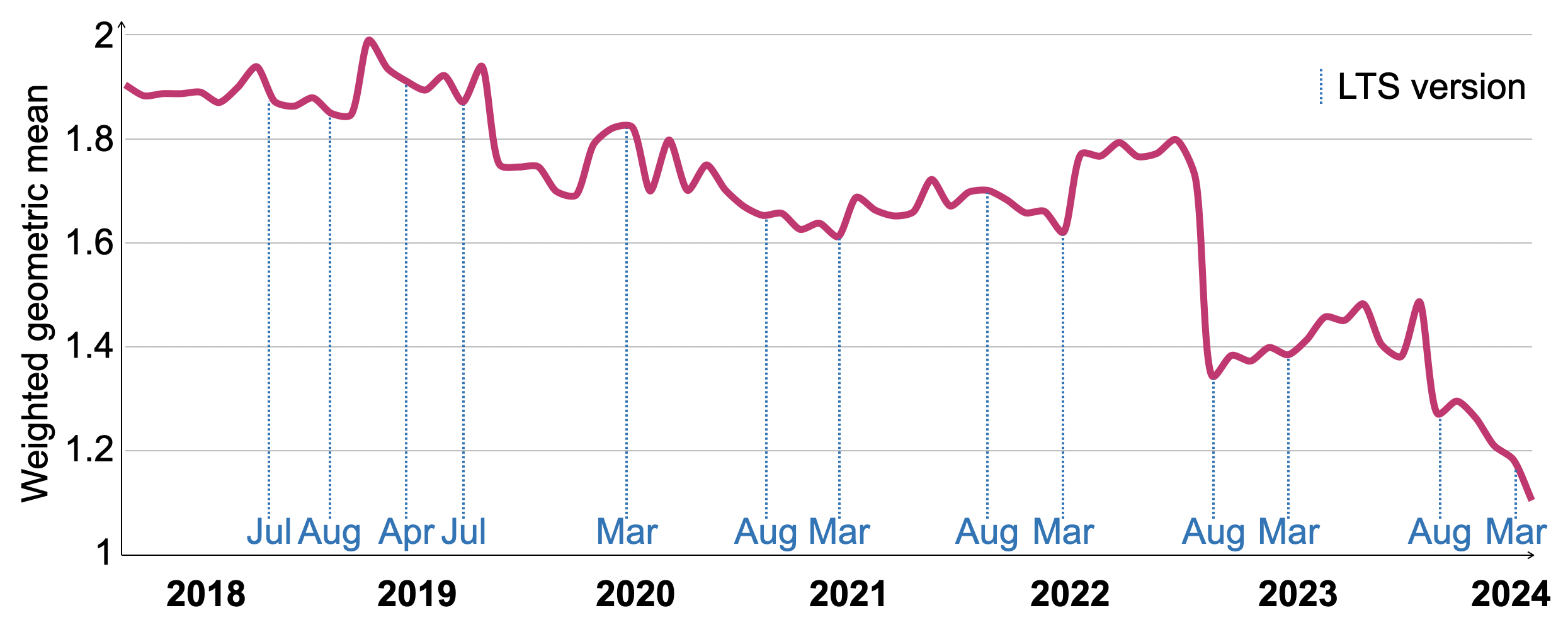
Рисунок 11: Относительное горячее время выполнения VersionsBench 2018-2024.
6.2.2 Нормализованные таблицы
В классическом хранилище данные часто моделируются с использованием звездных или снежинок схем. Мы представляем время выполнения запросов TPC-H (масштабный фактор 100), но отмечаем, что нормализованные таблицы являются развивающимся случаем использования для ClickHouse. Рисунок 12 показывает горячие времена выполнения запросов TPC-H, основанные на алгоритме параллельного хеш-джойна, описанном в разделе 4.4. Измерения были проведены на однонодовом экземпляре AWS EC2 c6i.16xlarge с 64 vCPUs, 128 ГБ RAM и 5000 IOPS / 1000 MiB/s диска. Было зарегистрировано самое быстрое из пяти запусков. Для справки мы провели те же измерения в системе Snowfake сопоставимого размера (размер склада L, 8x8 vCPUs, 8x16 ГБ RAM). Результаты одиннадцати запросов были исключены из таблицы: Запросы Q2, Q4, Q13, Q17 и Q20-22 включают коррелированные подзапросы, которые не поддерживаются с версии ClickHouse v24.6. Запросы Q7-Q9 и Q19 зависят от расширенных оптимизаций на уровне плана для соединений, таких как переупорядочивание соединений и продвижение предикатов соединений (обе отсутствуют на версии ClickHouse v24.6), чтобы достичь жизнеспособных времён выполнения. Автоматическая декорреляция подзапросов и лучшая поддержка оптимизаторов для соединений запланированы к реализации в 2024 году [18]. Из оставшихся 11 запросов 5 (6) запросов выполнялись быстрее в ClickHouse (Snowfake). Как упоминалось ранее, оптимизации известны как критически важные для производительности [27], и мы ожидаем, что они улучшат времена выполнения этих запросов еще больше после реализации.

Рисунок 12: Горячие времена выполнения (в секундах) для запросов TPC-H.
7 СМЕЖНЫЕ РАБОТЫ
Аналитические базы данных в последние десятилетия представляют собой большой академический и коммерческий интерес [1]. Ранние системы, такие как Sybase IQ [48], Teradata [72], Vertica [42] и Greenplum [47], характеризовались дорогими пакетными ETL-задачами и ограниченной эластичностью из-за их локальной природы. В начале 2010-х годов появление облачных хранилищ данных и предложений базы данных как услуги (DBaaS), таких как Snowfake [22], BigQuery [49] и Redshift [4], значительно снизило стоимость и сложность аналитики для организаций, одновременно получая преимущества от высокой доступности и автоматического масштабирования ресурсов. В последнее время аналитические исполнители (например, Photon [5] и Velox [62]) предлагают совместную обработку данных для использования в различных аналитических, потоковых и машинных приложениях.
Наиболее похожими базами данных на ClickHouse, с точки зрения целей и принципов проектирования, являются Druid [78] и Pinot [34]. Оба системы ориентированы на аналитику в реальном времени с высоким уровнем потребления данных. Как и ClickHouse, таблицы делятся на горизонтальные части, называемые сегментами. В то время как ClickHouse постоянно объединяет меньшие части и при необходимости сокращает объемы данных с использованием техник в разделе 3.3,, части остаются навсегда неизменяемыми в Druid и Pinot. Также Druid и Pinot требуют специализированные узлы для создания, мутации и поиска таблиц, в то время как ClickHouse использует монолитный бинарный файл для этих задач.
Snowfake [22] является популярным облачным хранилищем данных с собственным архитектурой, основанным на общей дисковой архитектуре. Его подход к делению таблиц на микропартии похож на концепцию частей в ClickHouse. Snowfake использует гибридные страницы PAX [3] для постоянного хранения, в то время как формат хранения ClickHouse строго столбцовый. Snowfake также подчеркивает локальное кэширование и обрезку данных с использованием автоматически создаваемых легковесных индексов [31, 51] как источник хорошей производительности. Аналогично первичным ключам в ClickHouse, пользователи могут по желанию создавать кластерные индексы, чтобы совместно размещать данные с одинаковыми значениями.
Photon [5] и Velox [62] являются движками выполнения запросов, предназначенными для использования в качестве компонентов в сложных системах управления данными. Оба система принимают планы запросов на вход, которые затем выполняются на локальном узле над файлами Parquet (Photon) или Arrow (Velox) [46]. ClickHouse может обрабатывать и генерировать данные в этих универсальных форматах, но предпочитает свой собственный формат файла для хранения. Хотя Velox и Photon не оптимизируют план запроса (Velox выполняет базовые оптимизации выражений), они используют техники адаптивности во время выполнения, такие как динамическое переключение вычислительных ядер в зависимости от характеристик данных. Аналогично, операторы плана в ClickHouse могут создавать другие операторы во время выполнения, в первую очередь для переключения на внешние агрегирующие или соединительные операторы, в зависимости от потребления памяти запроса. В статье по Photon отмечается, что дизайны с генерацией кода [38, 41, 53] сложнее разрабатывать и отлаживать, чем интерпретируемые векторизованные дизайны [11]. (экспериментальная) поддержка генерации кода в Velox строит и связывает общую библиотеку, созданную из сгенерированного во время выполнения кода C++, в то время как ClickHouse взаимодействует напрямую с API компиляции LLVM по запросу.
DuckDB [67] также предназначена для встраивания в основной процесс, но дополнительно предоставляет оптимизацию запросов и транзакции. Она была разработана для OLAP-запросов, смешанных с редкими операциями OLTP. DuckDB соответственно выбрала формат хранения DataBlocks [43], который использует легкие методы сжатия, такие как словари, сохраняющие порядок, или опорные кадры [2], чтобы достичь хорошей производительности в гибридных нагрузках. В отличие от этого, ClickHouse оптимизирован для случаев использования только с добавлением, т.е. без или редкими обновлениями и удалениями. Блоки сжимаются с использованием тяжелых техник, таких как LZ4, предполагая, что пользователи активно используют обрезку данных для ускорения частых запросов, и что затраты на ввод-вывод превосходят затраты на декомпрессию для оставшихся запросов. DuckDB также предоставляет сериализуемые транзакции на основе схемы MVCC Hyper [55], в то время как ClickHouse предлагает только изоляцию по снимкам.
8 ЗАКЛЮЧЕНИЕ И ПЕРСПЕКТИВЫ
Мы представили архитектуру ClickHouse, открытой высокопроизводительной OLAP базы данных. С оптимизированным для записи слоем хранения и современным векторизованным движком выполнения запросов в его основе, ClickHouse позволяет выполнять аналитику в реальном времени над данными объемом в петабайты с высокой скоростью потребления. Объединяя и преобразуя данные асинхронно в фоновом режиме, ClickHouse эффективно разгружает поддержку данных и параллельные вставки. Его слой хранения позволяет агрессивно выполнять обрезку данных с использованием разреженных первичных индексов, индексов пропуска и проекционных таблиц. Мы описали реализацию ClickHouse для обновлений и удалений, идемпотентных вставок и репликации данных между узлами для высокой доступности. Уровень обработки запросов оптимизирует запросы с помощью множества техник и параллелизует выполнение по всем ресурсам сервера и кластера. Табличные движки интеграции и функции предоставляют удобный способ бесшовного взаимодействия с другими системами управления данными и форматами данных. Через бенчмарки мы демонстрируем, что ClickHouse находится среди самых быстрых аналитических баз данных на рынке, и мы показали значительное улучшение производительности типичных запросов в реальных развертываниях ClickHouse на протяжении лет.
Все функции и улучшения, запланированные на 2024 год, можно найти на публичной дорожной карте [18]. Запланированные улучшения включают поддержку пользовательских транзакций, PromQL [69] как альтернативный язык запросов, новый тип данных для полуструктурированных данных (например, JSON), улучшенные оптимизации на уровне плана для соединений, а также реализацию легковесных обновлений в дополнение к легковесным удалениям.
9 БЛАГОДАРНОСТИ
Согласно версии 24.6, SELECT * FROM system.contributors возвращает 1994 человека, которые внесли вклад в ClickHouse. Мы хотели бы поблагодарить всю инженерную команду ClickHouse Inc. и удивительное сообщество open-source ClickHouse за их тяжелую работу и преданность в создании этой базы данных вместе.
ССЫЛКИ
- [1] Daniel Abadi, Peter Boncz, Stavros Harizopoulos, Stratos Idreaos, и Samuel Madden. 2013. Дизайн и реализация современных столбцовых систем управления базами данных. https://doi.org/10.1561/9781601987556
- [2] Daniel Abadi, Samuel Madden, и Miguel Ferreira. 2006. Интеграция сжатия и выполнения в столбцовых системах управления базами данных. В Материалах Международной конференции ACM SIGMOD по управлению данными (SIGMOD '06). 671–682. https://doi.org/10.1145/1142473.1142548
- [3] Anastassia Ailamaki, David J. DeWitt, Mark D. Hill, и Marios Skounakis. 2001. Плетение отношений для производительности кэша. В Материалах 27-й Международной конференции по очень большим базам данных (VLDB '01). Издательство Morgan Kaufmann, Сан-Франциско, CA, США, 169–180.
- [4] Nikos Armenatzoglou, Sanuj Basu, Naga Bhanoori, Mengchu Cai, Naresh Chainani, Kiran Chinta, Venkatraman Govindaraju, Todd J. Green, Monish Gupta, Sebastian Hillig, Eric Hotinger, Yan Leshinksy, Jintian Liang, Michael McCreedy, Fabian Nagel, Ippokratis Pandis, Panos Parchas, Rahul Pathak, Orestis Polychroniou, Foyzur Rahman, Gaurav Saxena, Gokul Soundararajan, Sriram Subramanian, и Doug Terry. 2022. Amazon Redshift переосмыслен. В Материалах Международной конференции по управлению данными 2022 года (Филадельфия, PA, США) (SIGMOD '22). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 2205–2217. https://doi.org/10.1145/3514221.3526045
- [5] Alexander Behm, Shoumik Palkar, Utkarsh Agarwal, Timothy Armstrong, David Cashman, Ankur Dave, Todd Greenstein, Shant Hovsepian, Ryan Johnson, Arvind Sai Krishnan, Paul Leventis, Ala Luszczak, Prashanth Menon, Mostafa Mokhtar, Gene Pang, Sameer Paranjpye, Greg Rahn, Bart Samwel, Tom van Bussel, Herman van Hovell, Maryann Xue, Reynold Xin, и Matei Zaharia. 2022. Photon: Быстрый движок запросов для систем Lakehouse (SIGMOD '22). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 2326–2339. https://doi.org/10.1145/3514221. 3526054
- [6] Philip A. Bernstein и Nathan Goodman. 1981. Контроль параллелизма в распределенных системах баз данных. ACM Computing Survey 13, 2 (1981), 185–221. https://doi.org/10.1145/356842.356846
- [7] Spyros Blanas, Yinan Li, и Jignesh M. Patel. 2011. Дизайн и оценка алгоритмов хеш-соединения в основной памяти для многоядерных ЦПУ. В Материалах Международной конференции ACM SIGMOD по управлению данными 2011 года (Афины, Греция) (SIGMOD '11). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 37–48. https://doi.org/10.1145/1989323.1989328
- [8] Daniel Gomez Blanco. 2023. Практический OpenTelemetry. Springer Nature.
- [9] Burton H. Bloom. 1970. Пространственные/временные компромиссы в хеш-编码 с допустимыми ошибками. Commun. ACM 13, 7 (1970), 422–426. https://doi.org/10.1145/362686. 362692
- [10] Peter Boncz, Thomas Neumann, и Orri Erling. 2014. TPC-H анализ: скрытые сообщения и уроки, извлеченные из влиятельного бенчмарка. В Характеризации производительности и бенчмаркинге. 61–76. https://doi.org/10.1007/978-3-319- 04936-6_5
- [11] Peter Boncz, Marcin Zukowski, и Niels Nes. 2005. MonetDB/X100: гиперпотоковая реализация запросов. В CIDR.
- [12] Martin Burtscher и Paruj Ratanaworabhan. 2007. Высокопроизводительное сжатие данных с плавающей запятой двойной точности. В Конференции по сжатию данных (DCC). 293–302. https://doi.org/10.1109/DCC.2007.44
- [13] Jef Carpenter и Eben Hewitt. 2016. Cassandra: Полное руководство (2-е изд.). O'Reilly Media, Inc.
- [14] Bernadette Charron-Bost, Fernando Pedone, и André Schiper (Ред.). 2010. Репликация: теория и практика. Springer-Verlag.
- [15] chDB. 2024. chDB - встроенный OLAP SQL движок. Получено 20 июня 2024 года с https://github.com/chdb-io/chdb
- [16] ClickHouse. 2024. ClickBench: бенчмаркинг для аналитических баз данных. Получено 20 июня 2024 года с https://github.com/ClickHouse/ClickBench
- [17] ClickHouse. 2024. ClickBench: Сравнительные измерения. Получено 20 июня 2024 года с https://benchmark.clickhouse.com
- [18] ClickHouse. 2024. Дорожная карта ClickHouse 2024 (GitHub). Получено 20 июня 2024 года с https://github.com/ClickHouse/ClickHouse/issues/58392
- [19] ClickHouse. 2024. Результаты бенчмарка версий ClickHouse. Получено 20 июня 2024 года с https://benchmark.clickhouse.com/versions/
- [20] ClickHouse. 2024. Результаты бенчмарка версий ClickHouse. Получено 20 июня 2024 года с https://github.com/ClickHouse/ClickBench/tree/main/versions
- [21] Andrew Crotty. 2022. MgBench. Получено 20 июня 2024 года с https://github.com/ andrewcrotty/mgbench
- [22] Benoit Dageville, Thierry Cruanes, Marcin Zukowski, Vadim Antonov, Artin Avanes, Jon Bock, Jonathan Claybaugh, Daniel Engovatov, Martin Hentschel, Jiansheng Huang, Allison W. Lee, Ashish Motivala, Abdul Q. Munir, Steven Pelley, Peter Povinec, Greg Rahn, Spyridon Triantafyllis, и Philipp Unterbrunner. 2016. Снежный эластичный склад данных. В Материалах Международной конференции 2016 года по управлению данными (Сан-Франциско, Калифорния, США) (SIGMOD '16). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 215–226. https: //doi.org/10.1145/2882903.2903741
- [23] Patrick Damme, Annett Ungethüm, Juliana Hildebrandt, Dirk Habich, и Wolfgang Lehner. 2019. От всестороннего экспериментального опроса к стратегии выбора на основе затрат для легковесных алгоритмов сжатия целых чисел. ACM Trans. Database Syst. 44, 3, Статья 9 (2019), 46 страниц. https://doi.org/10.1145/3323991
- [24] Philippe Dobbelaere и Kyumars Sheykh Esmaili. 2017. Kafka против RabbitMQ: сравнительное исследование двух промышленных реализаций распространения и подписки: Промышленная статья (DEBS '17). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 227–238. https://doi.org/10.1145/3093742.3093908
- [25] Документация LLVM. 2024. Авто-векторизация в LLVM. Получено 20 июня 2024 года с https://llvm.org/docs/Vectorizers.html
- [26] Siying Dong, Andrew Kryczka, Yanqin Jin, и Michael Stumm. 2021. RocksDB: Эволюция приоритетов разработки в хранилище ключ-значение для крупных приложений. ACM Transactions on Storage 17, 4, Статья 26 (2021), 32 страницы. https://doi.org/10.1145/3483840
- [27] Markus Dreseler, Martin Boissier, Tilmann Rabl, и Matthias Ufacker. 2020. Количественная оценка узких мест TPC-H и их оптимизации. Proc. VLDB Endow. 13, 8 (2020), 1206–1220. https://doi.org/10.14778/3389133.3389138
- [28] Ted Dunning. 2021. t-digest: эффективные оценки распределений. Software Impacts 7 (2021). https://doi.org/10.1016/j.simpa.2020.100049
- [29] Martin Faust, Martin Boissier, Marvin Keller, David Schwalb, Holger Bischof, Katrin Eisenreich, Franz Färber, и Hasso Plattner. 2016. Снижение размера и обеспечение уникальности с помощью хеш-индексов в SAP HANA. В Приложениях баз данных и экспертных систем. 137–151. https://doi.org/10.1007/978-3-319-44406- 2_11
- [30] Philippe Flajolet, Eric Fusy, Olivier Gandouet, и Frederic Meunier. 2007. HyperLogLog: анализ алгоритма оценки кардинальности, близкого к оптимальному. В AofA: Анализ алгоритмов, Т. DMTCS Proceedings vol. AH, 2007 Конференция по анализу алгоритмов (AofA 07). Дискретная математика и теоретическая информатика, 137–156. https://doi.org/10.46298/dmtcs.3545
- [31] Hector Garcia-Molina, Jefrey D. Ullman, и Jennifer Widom. 2009. Системы баз данных — Полная книга (2-е изд.).
- [32] Pawan Goyal, Harrick M. Vin, и Haichen Chen. 1996. Справедливое очередь по времени начала: алгоритм планирования для сетей интегрированных сервисов пакетной коммутации. 26, 4 (1996), 157–168. https://doi.org/10.1145/248157.248171
- [33] Goetz Graefe. 1993. Техники оценки запросов для крупных баз данных. ACM Comput. Surv. 25, 2 (1993), 73–169. https://doi.org/10.1145/152610.152611
- [34] Jean-François Im, Kishore Gopalakrishna, Subbu Subramaniam, Mayank Shrivastava, Adwait Tumbde, Xiaotian Jiang, Jennifer Dai, Seunghyun Lee, Neha Pawar, Jialiang Li, и Ravi Aringunram. 2018. Pinot: Реальное время OLAP для 530 миллионов пользователей. В Материалах Международной конференции 2018 года по управлению данными (Хьюстон, TX, США) (SIGMOD '18). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 583–594. https://doi.org/10.1145/3183713.3190661
- [35] ISO/IEC 9075-9:2001. 2001. Информационные технологии — Язык баз данных — SQL — Часть 9: Управление внешними данными (SQL/MED). Стандарт. Международная организация по стандартизации.
- [36] Paras Jain, Peter Kraft, Conor Power, Tathagata Das, Ion Stoica, и Matei Zaharia. 2023. Анализ и сравнение систем хранения Lakehouse. CIDR.
- [37] Project Jupyter. 2024. Jupyter Notebooks. Получено 20 июня 2024 года с https: //jupyter.org/
- [38] Timo Kersten, Viktor Leis, Alfons Kemper, Thomas Neumann, Andrew Pavlo, и Peter Boncz. 2018. Все, что вам когда-либо хотелось знать о скомпилированных и векторизованных запросах, но вы боялись спросить. Proc. VLDB Endow. 11, 13 (сентябрь 2018), 2209–2222. https://doi.org/10.14778/3275366.3284966
- [39] Changkyu Kim, Jatin Chhugani, Nadathur Satish, Eric Sedlar, Anthony D. Nguyen, Tim Kaldewey, Victor W. Lee, Scott A. Brandt, и Pradeep Dubey. 2010. FAST: быстрая архитектура, чувствительная к деревьям, для современных ЦПУ и ГПУ. В Материалах Международной конференции ACM SIGMOD по управлению данными 2010 года (Индиеанаполис, Индиана, США) (SIGMOD '10). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 339–350. https://doi.org/10.1145/1807167.1807206
- [40] Donald E. Knuth. 1973. Искусство программирования, Том III: Сортировка и поиск. Addison-Wesley.
- [41] André Kohn, Viktor Leis, и Thomas Neumann. 2018. Адаптивное выполнение скомпилированных запросов. В 2018 IEEE 34-й Международной конференции по инженерии данных (ICDE). 197–208. https://doi.org/10.1109/ICDE.2018.00027
- [42] Andrew Lamb, Matt Fuller, Ramakrishna Varadarajan, Nga Tran, Ben Vandiver, Lyric Doshi, и Chuck Bear. 2012. Vertica аналитическая база данных: C-Store через 7 лет. Proc. VLDB Endow. 5, 12 (август 2012), 1790–1801. https://doi.org/10. 14778/2367502.2367518
- [43] Harald Lang, Tobias Mühlbauer, Florian Funke, Peter A. Boncz, Thomas Neumann, и Alfons Kemper. 2016. Блоки данных: гибридный OLTP и OLAP на сжатом хранилище с использованием как векторизации, так и компиляции. В Материалах Международной конференции 2016 года по управлению данными (Сан-Франциско, Калифорния, США) (SIGMOD '16). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 311–326. https://doi.org/10.1145/2882903.2882925
- [44] Viktor Leis, Peter Boncz, Alfons Kemper, и Thomas Neumann. 2014. Параллелизм на основе Morsel: фреймворк оценки запросов с учетом NUMA для эпохи многих ядер. В Материалах Международной конференции ACM SIGMOD по управлению данными 2014 года (Сноубирд, Юта, США) (SIGMOD '14). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 743–754. https://doi.org/10.1145/2588555. 2610507
- [45] Viktor Leis, Alfons Kemper, и Thomas Neumann. 2013. Адаптивное дерево радиксов: ARTful индексация для баз данных в основной памяти. В 2013 IEEE 29-й Международной конференции по инженерии данных (ICDE). 38–49. https://doi.org/10.1109/ICDE. 2013.6544812
- [46] Chunwei Liu, Anna Pavlenko, Matteo Interlandi, и Brandon Haynes. 2023. Глубокое погружение в стандартные открытые форматы для аналитических СУБД. 16, 11 (июль 2023), 3044–3056. https://doi.org/10.14778/3611479.3611507
- [47] Zhenghua Lyu, Huan Hubert Zhang, Gang Xiong, Gang Guo, Haozhou Wang, Jinbao Chen, Asim Praveen, Yu Yang, Xiaoming Gao, Alexandra Wang, Wen Lin, Ashwin Agrawal, Junfeng Yang, Hao Wu, Xiaoliang Li, Feng Guo, Jiang Wu, Jesse Zhang, и Venkatesh Raghavan. 2021. Greenplum: Гибридная база данных для транзакционных и аналитических нагрузок (SIGMOD '21). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 2530–2542. https: //doi.org/10.1145/3448016.3457562
- [48] Roger MacNicol и Blaine French. 2004. Sybase IQ Multiplex - Разработано для аналитики. В Материалах Тридцатой Международной конференции по очень большим базам данных - Том 30 (Торонто, Канада) (VLDB '04). VLDB Endowment, 1227–1230.
- [49] Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geofrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis, Hossein Ahmadi, Dan Delorey, Slava Min, Mosha Pasumansky, и Jef Shute. 2020. Dremel: Десятилетие интерактивного SQL анализа в веб-масштабах. Proc. VLDB Endow. 13, 12 (август 2020), 3461–3472. https://doi.org/10.14778/3415478.3415568
- [50] Microsoft. 2024. Язык запросов Kusto. Получено 20 июня 2024 года с https: //github.com/microsoft/Kusto-Query-Language
- [51] Guido Moerkotte. 1998. Малые материализованные агрегаты: легковесная структура индекса для хранилищ данных. В Материалах 24-й Международной конференции по очень большим базам данных (VLDB '98). 476–487.
- [52] Jalal Mostafa, Sara Wehbi, Suren Chilingaryan, и Andreas Kopmann. 2022. SciTS: Бенчмарк для баз данных временных рядов в научных экспериментах и промышленном Интернете вещей. В Материалах 34-й Международной конференции по управлению научными и статистическими базами данных (SSDBM '22). Статья 12. https: //doi.org/10.1145/3538712.3538723
- [53] Thomas Neumann. 2011. Эффективная компиляция эффективных планов запросов для современного оборудования. Proc. VLDB Endow. 4, 9 (июнь 2011), 539–550. https://doi.org/10.14778/ 2002938.2002940
- [54] Thomas Neumann и Michael J. Freitag. 2020. Umbra: Дискосервис с производительностью в основной памяти. В 10-й конференции по инновационным исследованиям данных, CIDR 2020, Амстердам, Нидерланды, 12-15 января 2020 года, Онлайн-материалы. www.cidrdb.org. http://cidrdb.org/cidr2020/papers/p29-neumanncidr20.pdf
- [55] Thomas Neumann, Tobias Mühlbauer, и Alfons Kemper. 2015. Быстрый сериализуемый контроль параллелизма для систем баз данных в основной памяти. В Материалах Международной конференции ACM SIGMOD по управлению данными 2015 года (Мельбурн, Виктория, Австралия) (SIGMOD '15). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 677–689. https://doi.org/10.1145/2723372. 2749436
- [56] LevelDB на GitHub. 2024. LevelDB. Получено 20 июня 2024 года с https://github. com/google/leveldb
- [57] Patrick O'Neil, Elizabeth O'Neil, Xuedong Chen, и Stephen Revilak. 2009. Бенчмарк схем звезд и усовершенствованное индексирование фактов. В Оценке производительности и бенчмаркинге. Springer Berlin Heidelberg, 237–252. https: //doi.org/10.1007/978-3-642-10424-4_17
- [58] Patrick E. O'Neil, Edward Y. C. Cheng, Dieter Gawlick, и Elizabeth J. O'Neil. 1996. Дерево слияния на основе журнала (LSM-дерево). Acta Informatica 33 (1996), 351–385. https://doi.org/10.1007/s002360050048
- [59] Diego Ongaro и John Ousterhout. 2014. В поисках понятного алгоритма консенсуса. В Материалах конференции USENIX, посвященной техническому оснащению (USENIX ATC'14). 305–320. https://doi.org/doi/10. 5555/2643634.2643666
- [60] Patrick O'Neil, Edward Cheng, Dieter Gawlick, и Elizabeth O'Neil. 1996. Дерево слияния на базе журнала (LSM-дерево). Acta Inf. 33, 4 (1996), 351–385. https: //doi.org/10.1007/s002360050048
- [61] Pandas. 2024. Pandas Dataframes. Получено 20 июня 2024 года с https://pandas. pydata.org/
- [62] Pedro Pedreira, Orri Erling, Masha Basmanova, Kevin Wilfong, Laith Sakka, Krishna Pai, Wei He, и Biswapesh Chattopadhyay. 2022. Velox: Унифицированный движок выполнения Meta. Proc. VLDB Endow. 15, 12 (август 2022), 3372–3384. https: //doi.org/10.14778/3554821.3554829
- [63] Tuomas Pelkonen, Scott Franklin, Justin Teller, Paul Cavallaro, Qi Huang, Justin Meza, и Kaushik Veeraraghavan. 2015. Gorilla: Быстрая, масштабируемая база данных временных рядов в памяти. Материалы VLDB Endowment 8, 12 (2015), 1816–1827. https://doi.org/10.14778/2824032.2824078
- [64] Orestis Polychroniou, Arun Raghavan, и Kenneth A. Ross. 2015. Переосмысление векторизации SIMD для баз данных в основной памяти. В Материалах Международной конференции ACM SIGMOD по управлению данными 2015 года (SIGMOD '15). 1493–1508. https://doi.org/10.1145/2723372.2747645
- [65] PostgreSQL. 2024. PostgreSQL - Обертки для внешних данных. Получено 20 июня 2024 года с https://wiki.postgresql.org/wiki/Foreign_data_wrappers
- [66] Mark Raasveldt, Pedro Holanda, Tim Gubner, и Hannes Mühleisen. 2018. Справедливая бенчмаркинг считается сложной: Общие подводные камни в тестировании производительности баз данных. В Материалах семинара по тестированию систем баз данных (Хьюстон, TX, США) (DBTest'18). Статья 2, 6 страниц. https://doi.org/10.1145/3209950.3209955
- [67] Mark Raasveldt и Hannes Mühleisen. 2019. DuckDB: Встраиваемая аналитическая база данных (SIGMOD '19). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 1981–1984. https://doi.org/10.1145/3299869.3320212
- [68] Jun Rao и Kenneth A. Ross. 1999. Кэш-сознательное индексирование для поддержки принятия решений в основной памяти. В Материалах 25-й Международной конференции по очень большим базам данных (VLDB '99). Сан-Франциско, CA, США, 78–89.
- [69] Navin C. Sabharwal и Piyush Kant Pandey. 2020. Работа с языком запросов Prometheus (PromQL). В Мониторинг микросервисов и контейнеризованных приложений. https://doi.org/10.1007/978-1-4842-6216-0_5
- [70] Todd W. Schneider. 2022. Данные такси Нью-Йорка и автомобилей для найма. Получено 20 июня 2024 года с https://github.com/toddwschneider/nyc-taxi-data
- [71] Mike Stonebraker, Daniel J. Abadi, Adam Batkin, Xuedong Chen, Mitch Cherniack, Miguel Ferreira, Edmond Lau, Amerson Lin, Sam Madden, Elizabeth O'Neil, Pat O'Neil, Alex Rasin, Nga Tran, и Stan Zdonik. 2005. C-Store: Столбцовая СУБД. В Материалах 31-й Международной конференции по очень большим базам данных (VLDB '05). 553–564.
- [72] Teradata. 2024. Teradata Database. Получено 20 июня 2024 года с https://www. teradata.com/resources/datasheets/teradata-database
- [73] Frederik Transier. 2010. Алгоритмы и структуры данных для поисковых систем с текстом в памяти. Диссертация на соискание ученой степени. https://doi.org/10.5445/IR/1000015824
- [74] Adrian Vogelsgesang, Michael Haubenschild, Jan Finis, Alfons Kemper, Viktor Leis, Tobias Muehlbauer, Thomas Neumann, и Manuel Then. 2018. Споткнитесь: как бенчмарки не могут отражать реальность. В Материалах семинара по тестированию систем баз данных (Хьюстон, TX, США) (DBTest'18). Статья 1, 6 страниц. https://doi.org/10.1145/3209950.3209952
- [75] LZ4 сайт. 2024. LZ4. Получено 20 июня 2024 года с https://lz4.org/
- [76] PRQL сайт. 2024. PRQL. Получено 20 июня 2024 года с https://prql-lang.org [77] Till Westmann, Donald Kossmann, Sven Helmer, и Guido Moerkotte. 2000. Реализация и производительность сжатых баз данных. SIGMOD Rec.
- 29, 3 (сентябрь 2000), 55–67. https://doi.org/10.1145/362084.362137 [78] Fangjin Yang, Eric Tschetter, Xavier Léauté, Nelson Ray, Gian Merlino, и Deep Ganguli. 2014. Druid: Система аналитических данных в реальном времени. В Материалах Международной конференции ACM SIGMOD по управлению данными 2014 года (Сноубирд, Юта, США) (SIGMOD '14). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 157–168. https://doi.org/10.1145/2588555.2595631
- [79] Tianqi Zheng, Zhibin Zhang, и Xueqi Cheng. 2020. SAHA: Строка адаптивной хеш-таблицы для аналитических баз данных. Прикладные науки 10, 6 (2020). https: //doi.org/10.3390/app10061915
- [80] Jingren Zhou и Kenneth A. Ross. 2002. Реализация операций баз данных с использованием инструкций SIMD. В Материалах Международной конференции ACM SIGMOD по управлению данными 2002 года (SIGMOD '02). 145–156. https://doi.org/10. 1145/564691.564709
- [81] Marcin Zukowski, Sandor Heman, Niels Nes, и Peter Boncz. 2006. Сжатие кэша RAM-ЦПУ суперскаляров. В Материалах 22-й Международной конференции по инженерии данных (ICDE '06). 59. https://doi.org/10.1109/ICDE. 2006.150